



































![Five Nights At Freddy's – Walkthrough [1] DON'T WATCH AT NIGHT!! (+Download)](https://techcratic.com/wp-content/uploads/2024/11/1731599476_maxresdefault-360x180.jpg)

























2024-10-13 19:13:00
sihyun.me
1KAIST
2Korea University
3Scaled Foundations
4New York University
*Equal Advising.

News
[Oct 2024] Our project page is released.
Overview
Generative models based on denoising, such as diffusion models and flow-based models, have been a scalable
approach in generating high-dimensional visual data. Recent works have started exploring diffusion models as
representation learners; the idea is that the hidden states of these models can capture meaningful, discriminative features.
We identify that the main challenge in training diffusion models stems from the need to learn a high-quality internal representation.
In particular, we show:
The performance of generative diffusion models can be improved dramatically when they are supported by an
external high-quality representation from another model, such as a self-supervised visual encoder.
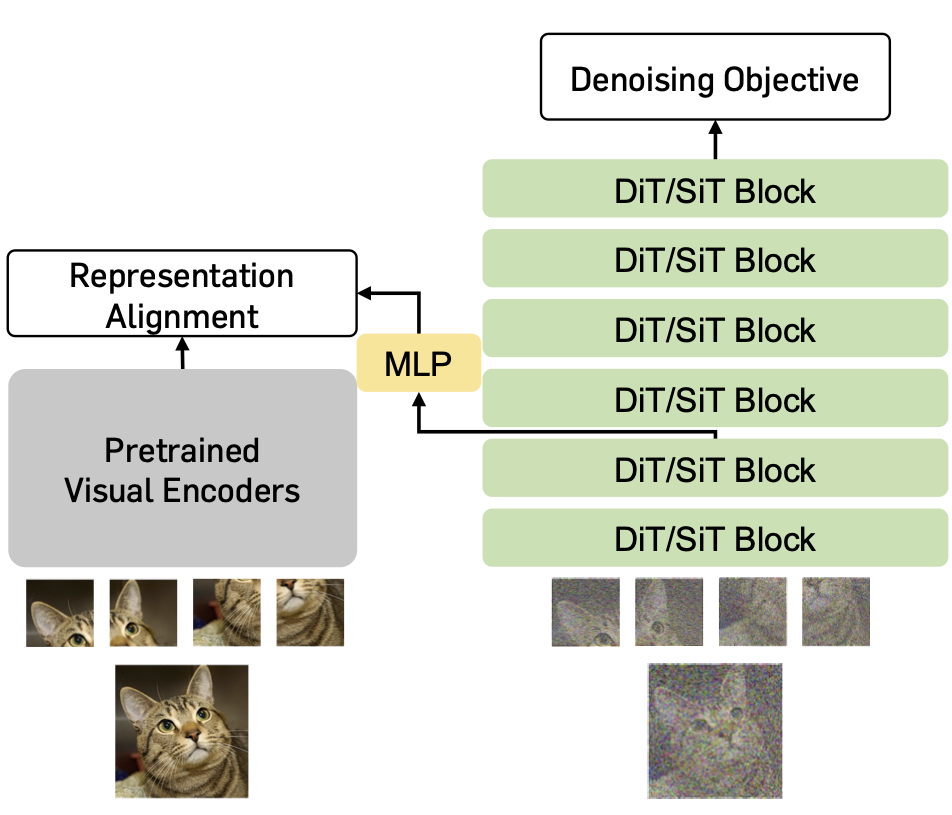
Specifically, we introduce REPresentation Alignment (REPA), a simple regularization technique
built on recent diffusion transformer architectures.
In essence, REPA distills the pretrained self-supervised visual representation of a clean image into
the diffusion transformer representation of a noisy input. This regularization better aligns
the diffusion model representations with the target self-supervised representations.
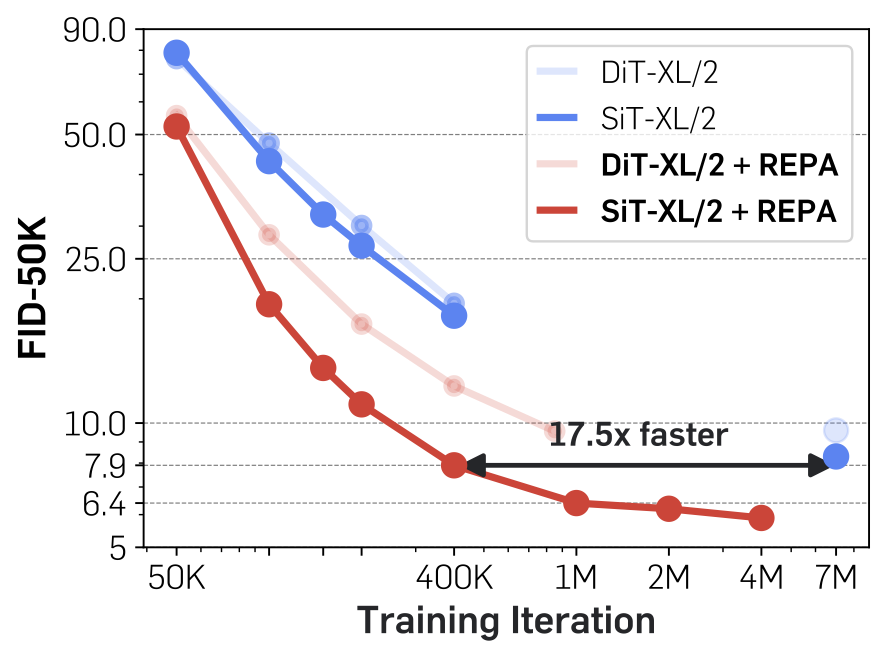
Notably, model training becomes significantly
more efficient and effective, and achieves >17.5x faster convergence than the vanilla model.
In terms of final generation quality, our approach achieves state-of-the-art results of FID=1.42
using classifier-free guidance with the guidance interval.
Observations
Alignment behavior for a pretrained SiT model
We empirically investigate the feature alignment between DINOv2-g
and the original SiT-XL/2 checkpoint
trained for 7M iterations.
Similar to prior studies, we first observe that pretrained diffusion models do indeed learn meaningful
discriminative representations. However, these representations
are significantly inferior to those produced by DINOv2. Next, we find that the alignment between the
representations learned by the diffusion model and those of DINOv2 is still considered weak,
which we study by measuring their representation alignment.
Finally, we observe this alignment between diffusion models and DINOv2 improves consistently with longer
training and larger models.
Bridging the representation gap
REPA reduces the semantic gap in the representation and better aligns it with the target self-supervised
representations. Interestingly, with REPA, we observe that sufficient representation alignment
can be achieved by aligning only the first few transformer blocks. This, in turn, allows the later layers
of the diffusion transformers to focus on capturing high-frequency details based on the aligned representations,
further improving generation performance.
Results
REPA improves visual scaling
We first compare the images generated by two SiT-XL/2 models during the first 400K iterations, with REPA
applied to one of the models. Both models share the same noise, sampler, and number of sampling steps,
and neither uses classifier-free guidance. The model trained with REPA shows much better progression.

REPA shows great scalability in various perspectives
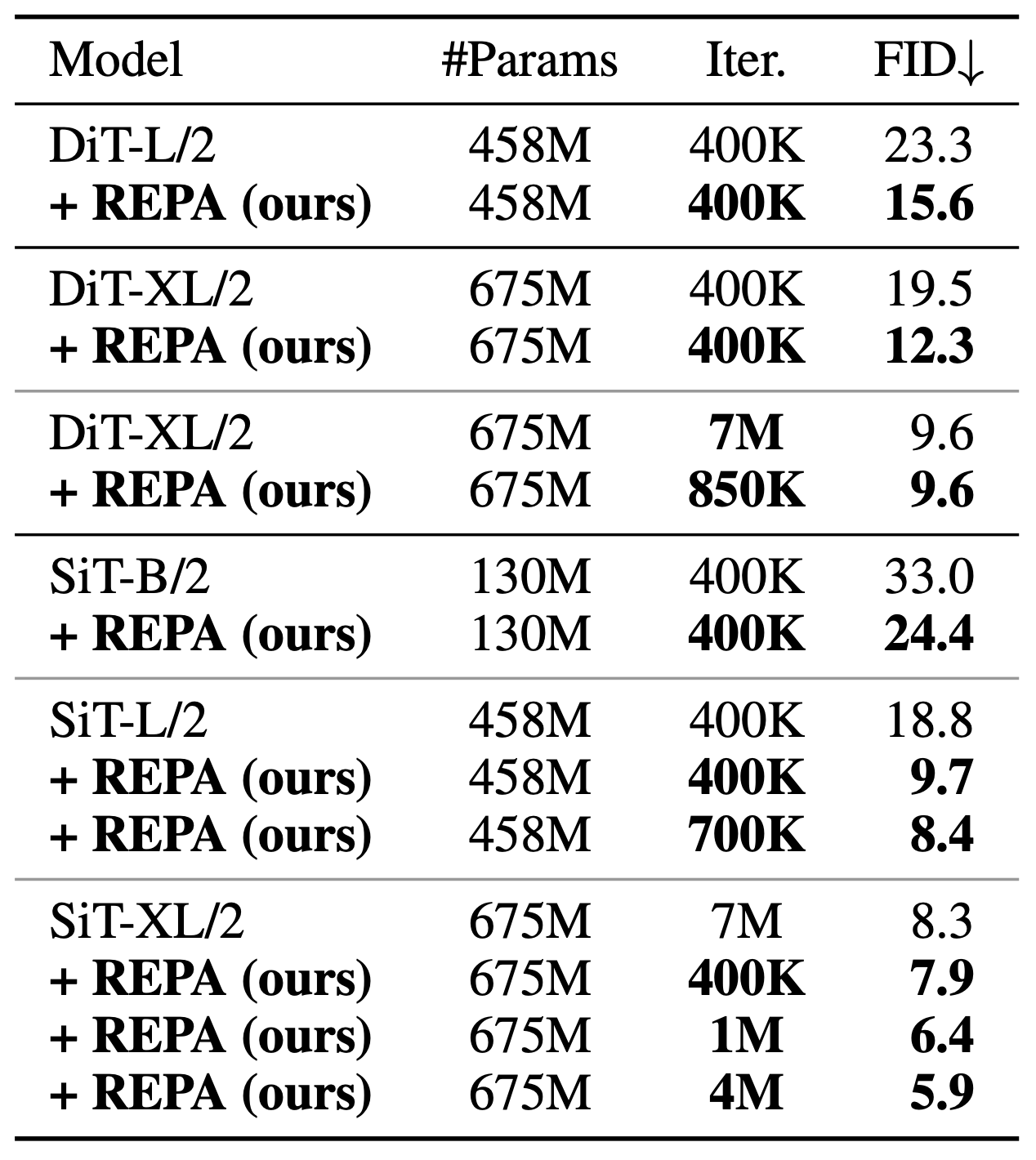
We also examine the scalability of REPA by varying pretrained encoders and diffusion transformer model sizes,
showing that aligning with better visual representations leads to improved generation and linear probing results.
REPA also provides more significant speedups in larger models, achieving faster FID-50K improvements compared to
vanilla models. Additionally, increasing model size yields faster gains in both generation and linear evaluation.
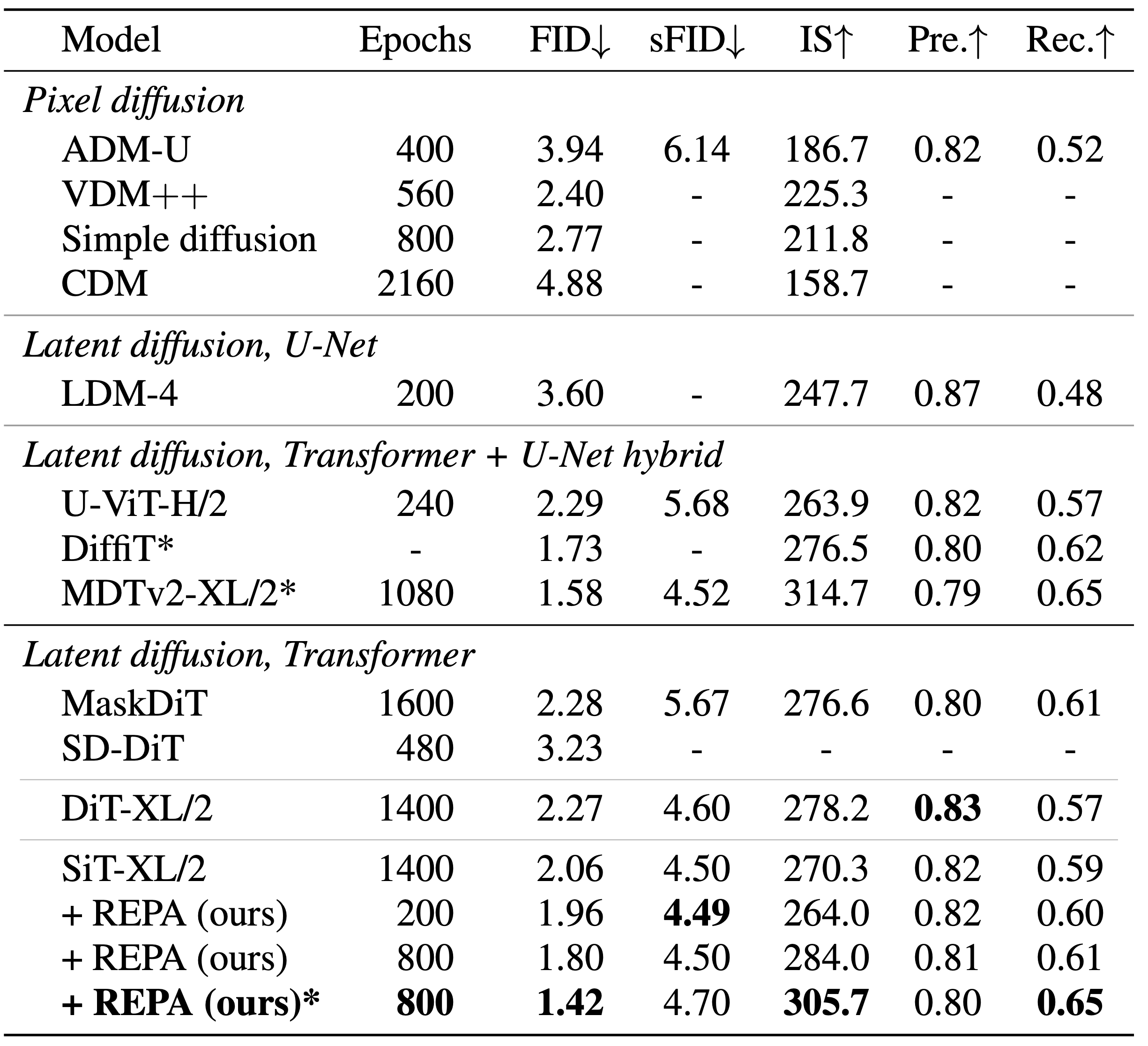
REPA significantly improves training efficiency and generation quality
Finally, we compare the FID values between vanilla DiT or SiT models and those trained with REPA.
Without classifier-free guidance, REPA achieves FID=7.9 at 400K iterations,
outperforming the vanilla model’s performance at 7M iterations. Moreover, using classifier-free guidance,
SiT-XL/2 with REPA outperforms recent diffusion models with 7× fewer epochs, and achieves state-of-the-art FID=1.42
with additional guidance scheduling.
Citation
@article{yu2024repa,
title={Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think},
author={Sihyun Yu and Sangkyung Kwak and Huiwon Jang and Jongheon Jeong and Jonathan Huang and Jinwoo Shin and Saining Xie},
year={2024},
journal={arXiv preprint arXiv:2410.06940},
}Support Techcratic
If you find value in Techcratic’s insights and articles, consider supporting us with Bitcoin. Your support helps me, as a solo operator, continue delivering high-quality content while managing all the technical aspects, from server maintenance to blog writing, future updates, and improvements. Support Innovation! Thank you.
Bitcoin Address:
bc1qlszw7elx2qahjwvaryh0tkgg8y68enw30gpvge
Please verify this address before sending funds.
Bitcoin QR Code
Simply scan the QR code below to support Techcratic.

Please read the Privacy and Security Disclaimer on how Techcratic handles your support.
Disclaimer: As an Amazon Associate, Techcratic may earn from qualifying purchases.

![The geometry of data: the missing metric tensor and the Stein score [Part II]](https://techcratic.com/wp-content/uploads/2024/11/lensing-360x180.jpg)



