



































![Five Nights At Freddy's – Walkthrough [1] DON'T WATCH AT NIGHT!! (+Download)](https://techcratic.com/wp-content/uploads/2024/11/1731599476_maxresdefault-360x180.jpg)

























2024-10-15 14:08:00
engineering.fb.com
- At the Open Compute Project (OCP) Global Summit 2024, we’re showcasing our latest open AI hardware designs with the OCP community.
- These innovations include a new AI platform, cutting-edge open rack designs, and advanced network fabrics and components.
- By sharing our designs, we hope to inspire collaboration and foster innovation. If you’re passionate about building the future of AI, we invite you to engage with us and OCP to help shape the next generation of open hardware for AI.
AI has been at the core of the experiences Meta has been delivering to people and businesses for years, including AI modeling innovations to optimize and improve on features like Feed and our ads system. As we develop and release new, advanced AI models, we are also driven to advance our infrastructure to support our new and emerging AI workloads.
For example, Llama 3.1 405B, Meta’s largest model, is a dense transformer with 405B parameters and a context window of up to 128k tokens. To train a large language model (LLM) of this magnitude, with over 15 trillion tokens, we had to make substantial optimizations to our entire training stack. This effort pushed our infrastructure to operate across more than 16,000 NVIDIA H100 GPUs, making Llama 3.1 405B the first model in the Llama series to be trained at such a massive scale.
Prior to Llama, our largest AI jobs ran on 128 NVIDIA A100 GPUs. But things have rapidly accelerated. Over the course of 2023, we rapidly scaled up our training clusters from 1K, 2K, 4K, to eventually 16K GPUs to support our AI workloads. Today, we’re training our models on two 24K-GPU clusters.
We don’t expect this upward trajectory for AI clusters to slow down any time soon. In fact, we expect the amount of compute needed for AI training will grow significantly from where we are today.
Building AI clusters requires more than just GPUs. Networking and bandwidth play an important role in ensuring the clusters’ performance. Our systems consist of a tightly integrated HPC compute system and an isolated high-bandwidth compute network that connects all our GPUs and domain-specific accelerators. This design is necessary to meet our injection needs and address the challenges posed by our need for bisection bandwidth.
In the next few years, we anticipate greater injection bandwidth on the order of a terabyte per second, per accelerator, with equal normalized bisection bandwidth. This represents a growth of more than an order of magnitude compared to today’s networks!
To support this growth, we need a high-performance, multi-tier, non-blocking network fabric that can utilize modern congestion control to behave predictably under heavy load. This will enable us to fully leverage the power of our AI clusters and ensure they continue to perform optimally as we push the boundaries of what is possible with AI.
Scaling AI at this speed requires open hardware solutions. Developing new architectures, network fabrics, and system designs is the most efficient and impactful when we can build it on principles of openness. By investing in open hardware, we unlock AI’s full potential and propel ongoing innovation in the field.
Introducing Catalina: Open Architecture for AI Infra

Today, we announced the upcoming release of Catalina, our new high-powered rack designed for AI workloads, to the OCP community. Catalina is based on the NVIDIA Blackwell platform full rack-scale solution, with a focus on modularity and flexibility. It is built to support the latest NVIDIA GB200 Grace Blackwell Superchip, ensuring it meets the growing demands of modern AI infrastructure.
The growing power demands of GPUs means open rack solutions need to support higher power capability. With Catalina we’re introducing the Orv3, a high-power rack (HPR) capable of supporting up to 140kW.
The full solution is liquid cooled and consists of a power shelf that supports a compute tray, switch tray, the Orv3 HPR, the Wedge 400 fabric switch, a management switch, battery backup unit, and a rack management controller.
We aim for Catalina’s modular design to empower others to customize the rack to meet their specific AI workloads while leveraging both existing and emerging industry standards.
The Grand Teton Platform now supports AMD accelerators

In 2022, we announced Grand Teton, our next-generation AI platform (the follow-up to our Zion-EX platform). Grand Teton is designed with compute capacity to support the demands of memory-bandwidth-bound workloads, such as Meta’s deep learning recommendation models (DLRMs), as well as compute-bound workloads like content understanding.
Now, we have expanded the Grand Teton platform to support the AMD Instinct MI300X and will be contributing this new version to OCP. Like its predecessors, this new version of Grand Teton features a single monolithic system design with fully integrated power, control, compute, and fabric interfaces. This high level of integration simplifies system deployment, enabling rapid scaling with increased reliability for large-scale AI inference workloads.
In addition to supporting a range of accelerator designs, now including the AMD Instinct MI300x, Grand Teton offers significantly greater compute capacity, allowing faster convergence on a larger set of weights. This is complemented by expanded memory to store and run larger models locally, along with increased network bandwidth to scale up training cluster sizes efficiently.
Open Disaggregated Scheduled Fabric
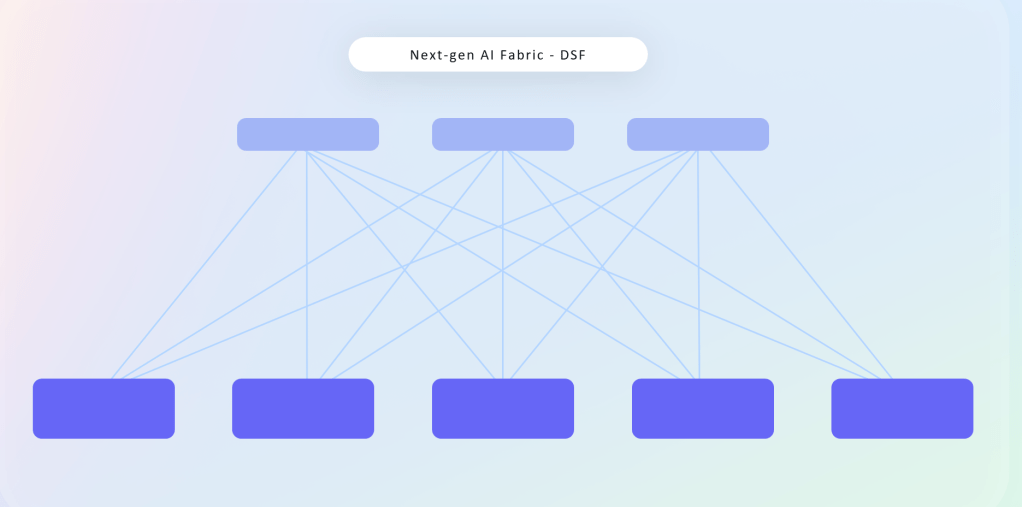
Developing open, vendor-agnostic networking backend is going to play an important role going forward as we continue to push the performance of our AI training clusters. Disaggregating our network allows us to work with vendors from across the industry to design systems that are innovative as well as scalable, flexible, and efficient.
Our new Disaggregated Scheduled Fabric (DSF) for our next-generation AI clusters offers several advantages over our existing switches. By opening up our network fabric we can overcome limitations in scale, component supply options, and power density. DSF is powered by the open OCP-SAI standard and FBOSS, Meta’s own network operating system for controlling network switches. It also supports an open and standard Ethernet-based RoCE interface to endpoints and accelerators across several GPUS and NICS from several different vendors, including our partners at NVIDIA, Broadcom, and AMD.
In addition to DSF, we have also developed and built new 51T fabric switches based on Broadcom and Cisco ASICs. Finally, we are sharing our new FBNIC, a new NIC module that contains our first Meta-design network ASIC. In order to meet the growing needs of our AI
Meta and Microsoft: Driving Open Innovation Together
Meta and Microsoft have a long-standing partnership within OCP, beginning with the development of the Switch Abstraction Interface (SAI) for data centers in 2018. Over the years together, we’ve contributed to key initiatives such as the Open Accelerator Module (OAM) standard and SSD standardization, showcasing our shared commitment to advancing open innovation.
Our current collaboration focuses on Mount Diablo, a new disaggregated power rack. It’s a cutting-edge solution featuring a scalable 400 VDC unit that enhances efficiency and scalability. This innovative design allows more AI accelerators per IT rack, significantly advancing AI infrastructure. We’re excited to continue our collaboration through this contribution.
The open future of AI infra
Meta is committed to open source AI. We believe that open source will put the benefits and opportunities of AI into the hands of people all over the word.
AI won’t realize its full potential without collaboration. We need open software frameworks to drive model innovation, ensure portability, and promote transparency in AI development. We must also prioritize open and standardized models so we can leverage collective expertise, make AI more accessible, and work towards minimizing biases in our systems.
Just as important, we also need open AI hardware systems. These systems are necessary for delivering the kind of high-performance, cost-effective, and adaptable infrastructure necessary for AI advancement.
We encourage anyone who wants to help advance the future of AI hardware systems to engage with the OCP community. By addressing AI’s infrastructure needs together, we can unlock the true promise of open AI for everyone.
Support Techcratic
If you find value in Techcratic’s insights and articles, consider supporting us with Bitcoin. Your support helps me, as a solo operator, continue delivering high-quality content while managing all the technical aspects, from server maintenance to blog writing, future updates, and improvements. Support Innovation! Thank you.
Bitcoin Address:
bc1qlszw7elx2qahjwvaryh0tkgg8y68enw30gpvge
Please verify this address before sending funds.
Bitcoin QR Code
Simply scan the QR code below to support Techcratic.

Please read the Privacy and Security Disclaimer on how Techcratic handles your support.
Disclaimer: As an Amazon Associate, Techcratic may earn from qualifying purchases.

![The geometry of data: the missing metric tensor and the Stein score [Part II]](https://techcratic.com/wp-content/uploads/2024/11/lensing-360x180.jpg)



