




















































![Friends: The Complete Series (4K UltraHD) [4K UHD]](https://techcratic.com/wp-content/uploads/2024/11/71zFLJVDUeL._SL1500_-360x180.jpg)




![#UFO FLEET | MUFON CASE # 106156 [MUST SEE] Louisiana](https://techcratic.com/wp-content/uploads/2024/11/1732148641_maxresdefault-360x180.jpg)




Image by Editor | Midjourney
Interaction is all about contact, which means how you narrate a story to your users, how they comprehend it, and how they may engage with it. People love to see things with their eyes, they love projections they can interact with.
An interactive application is computer software built to engage users in active engagement. This indicates that when a user clicks a button, types text, or moves an object on the screen, the program reacts to those actions. It looks like a dialogue where you perform an act, and the computer reacts.
An interactive application comprises of these major features, user input (where users can input data or commands), feedback (this is the result of the user input), and multimedia elements (e.g., images, videos, and audio used to make the application interaction more engaging).
Our Top 3 Partner Recommendations
![]()
![]() 1. Best VPN for Engineers – 3 Months Free – Stay secure online with a free trial
1. Best VPN for Engineers – 3 Months Free – Stay secure online with a free trial
![]()
![]() 2. Best Project Management Tool for Tech Teams – Boost team efficiency today
2. Best Project Management Tool for Tech Teams – Boost team efficiency today
![]()
![]() 4. Best Password Management for Tech Teams – zero-trust and zero-knowledge security
4. Best Password Management for Tech Teams – zero-trust and zero-knowledge security
Some examples of interactive applications are educational software, social media applications, computer video games, etc. A very good example of a computer software that’s not interactive your a computer screen saver, which requires no user interaction while running.
Libraries Providing Interactivity in Data Science
Back then, you would have to present your data science applications using Flask or learn HTML, CSS, and JavaScript. But right now, things have gotten a lot better and easier since the introduction of interactive data science web libraries, these frameworks give data scientists the flexibility to build interactive data science applications without the hassle of learning front-end technologies, sharing data applications, deploying applications on the cloud with just the Python programming language.
Some of these libraries include:
- Streamlit
- Gradio
- Dash
- Panel
Streamlit
Streamlit is an open-source Python framework used to build highly interactive data apps in only a few lines of code. Its primary purpose when it was created in 2019 was to help you focus and concentrate on what matters most to you: your data analysis!
Streamlit functions by transforming Python scripts into web apps that can be shared. Streamlit’s simplicity is what makes it so popular. Using the Streamlit library is simple and quick, so you don’t need any prior web programming skills to create data apps. Learn more about Streamlit here.
Even though Streamlit is an excellent tool, its usefulness can differ based on the situation. All your applications will have the same layout and style unless you are ready to create some HTML, JS, and CSS because Streamlit apps have rather rigid designs and appearances.
Gradio
Gradio is an open-source web framework that makes creating machine learning (ML) applications easier. It spares developers from developing any front-end code and enables you to easily construct interfaces for ML models.
Developers use Gradio to construct interfaces for text, graphic, or audio-based models. Gradio also supports many well-known ML frameworks, including TensorFlow, PyTorch, and Scikit-learn.
Gradio is more suited for machine learning demonstrations, whereas Streamlit is more focused on data dashboard creation. This is the primary distinction between the two languages. Its drag-and-drop interface makes creating custom input fields and outputs easy, and its integrated support for hosting and sharing machine learning models simplifies the deployment process.
Some Gradio applications may appear pretty old and out of date. Therefore, you must know how to write basic CSS to customize them. Unlike Streamlit applications, which perform better as independent apps, Gradio apps function best when embedded into another webpage.
Dash
Dash is an open-source framework for creating data applications with Python, R, or Julia. It’s a great tool for making data-driven, interactive dashboards, and it has the advantage of being a low-code framework for quickly developing Python data applications.
Dash includes an HTML wrapper in Python for creating user interfaces, but using it still requires knowledge of HTML. It is also not as simple to get started with as Streamlit because it is a little more complex (you’ll need to utilize “callbacks” and some HTML).
Panel
Panel is an open-source Python toolkit intended to make it easier to create powerful tools, dashboards, and intricate applications using just Python. Panel’s broad approach allows it to effortlessly connect with the PyData ecosystem while providing strong, interactive data tables, visualizations, and much more to let you unlock, analyze, share, and work together on your data for productive workflows.
Its feature set includes both low-level callback-based APIs and high-level reactive APIs, which make it easier to create complex, multi-page apps with a lot of interactivity and to quickly design exploratory applications.
Similar to all of the available solutions, Panel facilitates the easy running and hosting of your apps locally; however, you are on your own when it comes to deploying them to the cloud. They do offer instructions on several deployment choices
Building Interactive Data Apps with Streamlit
In this section, you will build a fully functional and interactive dashboard that shows the visualizations and data of the United States population for the years 2010-2019 from the US Census Bureau.
Here is the application demo:

Note: If you want to test the application, you can check it out here but, If you want to jump ahead and have a look at the code, feel free to check it out here
Requirements
- Python 3.5+
- Streamlit
pip install streamlit - Pandas – for data analysis and wrangling
- Altair – this is a Python visualization library
- Plotly Express – this library is used as a high-level API for creating figures
Dataset
The dataset from the US Census Bureau that will be used for our dashboard has three important columns (states, year, and population), which will serve as the primary basis for our metrics.
The image below shows what the dataset looks like:

Import the Required Libraries
import streamlit as st
import pandas as pd
import altair as alt
import plotly.express as px
Configure the Page
The next step is to specify the application’s settings by assigning it a browser-displayed page title and icon. This specifies how the sidebar will be shown when it is enlarged and how the page content will be presented in a wide layout that matches the width of the page.
We can adjust the Altair plot’s color theme to match the app’s dark color scheme.
st.set_page_config(
page_title="USA Population Trends",
page_icon="🇺🇸",
layout="wide",
initial_sidebar_state="expanded")
alt.themes.enable("dark")
Import Data
Load the dataset into the project using Pandas.
population_data = pd.read_csv('data/us-population-census-2010-2019.csv')
Sidebar Configuration
Using st.title(), we will build the app title. Using st.selectbox(), we will create drop-down widgets that let users choose a certain year and color theme.
After that, the data for that year will be subset using the chosen_year (from the years that are accessible from 2010 to 2019), and it will be shown in-app. Using the chosen_palette, the heatmap and choropleth map can be colored according to the color provided by the aforementioned widget.
with st.sidebar:
st.title('🇺🇸 USA Population Trends')
available_years = list(population_data.year.unique())[::-1]
chosen_year = st.selectbox('Choose a year', available_years)
year_data = population_data[population_data.year == chosen_year]
sorted_year_data = year_data.sort_values(by="population", ascending=False)
palette_options = ['blues', 'greens', 'reds', 'purples', 'oranges', 'greys']
chosen_palette = st.selectbox('Choose a color palette', palette_options)
Plot and Chart Types
We will make use of three charts, namely, heatmap, Choropleth map, and Donut chart. Let’s go ahead to define a custom function to display the various plots.
Heatmap
The function create_heat_map() will be used to display the heatmap of the US population for the year 2010 – 2019.
# Heatmap
def create_heat_map(data, y_axis, x_axis, color_var, color_scheme):
heat_map = alt.Chart(data).mark_rect().encode(
y=alt.Y(f'{y_axis}:O', axis=alt.Axis(title="Year", titleFontSize=18, titlePadding=15, titleFontWeight=900, labelAngle=0)),
x=alt.X(f'{x_axis}:O', axis=alt.Axis(title="", titleFontSize=18, titlePadding=15, titleFontWeight=900)),
color=alt.Color(f'max({color_var}):Q',
legend=None,
scale=alt.Scale(scheme=color_scheme)),
stroke=alt.value('black'),
strokeWidth=alt.value(0.25),
).properties(width=900
).configure_axis(
labelFontSize=12,
titleFontSize=12
)
# height=300
return heat_map
Here is the output:
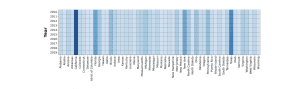
Choropleth Map
The function create_choropleth() will display a colored map of the 52 states in the US for the selected year.
# Choropleth map
def create_choropleth(data, location_col, color_col, color_scheme):
map_plot = px.choropleth(data, locations=location_col, color=color_col, locationmode="USA-states",
color_continuous_scale=color_scheme,
range_color=(0, max(year_data.population)),
scope="usa",
labels={'population':'Population'}
)
map_plot.update_layout(
template="plotly_dark",
plot_bgcolor="rgba(0, 0, 0, 0)",
paper_bgcolor="rgba(0, 0, 0, 0)",
margin=dict(l=0, r=0, t=0, b=0),
height=350
)
return map_plot
Here is the output:
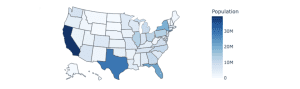
Donut Chart
The last chart we’ll make is a donut chart, which will show the percentage migration of each state. Before making the donut graphic, we must determine the population movements from year to year.
# Donut chart
def create_donut(value, label, color):
color_map = {
'blue': ['#29b5e8', '#155F7A'],
'green': ['#27AE60', '#12783D'],
'red': ['#E74C3C', '#781F16'],
'purple': ['#8E44AD', '#4A235A']
}
chart_colors = color_map.get(color, ['#F39C12', '#875A12'])
data = pd.DataFrame({
"Category": ['', label],
"Percentage": [100-value, value]
})
background = pd.DataFrame({
"Category": ['', label],
"Percentage": [100, 0]
})
chart = alt.Chart(data).mark_arc(innerRadius=45, cornerRadius=25).encode(
theta="Percentage",
color= alt.Color("Category:N",
scale=alt.Scale(domain=[label, ''], range=chart_colors),
legend=None),
).properties(width=130, height=130)
text = chart.mark_text(align='center', color="#29b5e8", font="Lato", fontSize=32, fontWeight=700, fontStyle="italic").encode(text=alt.value(f'{value} %'))
background_chart = alt.Chart(background).mark_arc(innerRadius=45, cornerRadius=20).encode(
theta="Percentage",
color= alt.Color("Category:N",
scale=alt.Scale(domain=[label, ''], range=chart_colors),
legend=None),
).properties(width=130, height=130)
return background_chart + chart + text
Output:

Convert Population to Text
The next step will be to develop a custom function to condense population values. In particular, the metrics card’s presentation of the values is reduced from 28,995,881 to a more manageable 29.0 M. This goes for the numbers within the thousand range.
# Convert population to text
def format_population(number):
if number > 1000000:
if not number % 1000000:
return f'{number // 1000000} M'
return f'{round(number / 1000000, 1)} M'
return f'{number // 1000} K'
# Calculation year-over-year population migrations
def compute_population_change(data, target_year):
current_year = data[data['year'] == target_year].reset_index()
previous_year = data[data['year'] == target_year - 1].reset_index()
current_year['population_change'] = current_year.population.sub(previous_year.population, fill_value=0)
return pd.concat([current_year.states, current_year.id, current_year.population, current_year.population_change], axis=1).sort_values(by="population_change", ascending=False)
Here is the output:

Define the App Layout
Now that we have all the pieces ready let’s put them all together in the app by defining the app layout. Start by creating 3 columns:
columns = st.columns((1.5, 4.5, 2), gap='medium')
The input arguments (1.5, 4.5, 2) show that the second column is the largest, with a width that is about three times of the first column.
First Column
This column contains the metrics card displaying the states with the highest inbound and outward migration for the chosen year. This column also contains the donut chart showing the state’s migration, both inbound and outbound.
with columns[0]:
st.markdown('#### Population Changes')
population_change_data = compute_population_change(population_data, chosen_year)
if chosen_year > 2010:
top_state = population_change_data.states.iloc[0]
top_state_pop = format_population(population_change_data.population.iloc[0])
top_state_change = format_population(population_change_data.population_change.iloc[0])
bottom_state = population_change_data.states.iloc[-1]
bottom_state_pop = format_population(population_change_data.population.iloc[-1])
bottom_state_change = format_population(population_change_data.population_change.iloc[-1])
else:
top_state = bottom_state="-"
top_state_pop = bottom_state_pop = '-'
top_state_change = bottom_state_change=""
st.metric(label=top_state, value=top_state_pop, delta=top_state_change)
st.metric(label=bottom_state, value=bottom_state_pop, delta=bottom_state_change)
st.markdown('#### Migration Trends')
if chosen_year > 2010:
growing_states = population_change_data[population_change_data.population_change > 50000]
shrinking_states = population_change_data[population_change_data.population_change
Second Column
The second column, which is the largest column, displays the choropleth map and heatmap using custom functions that were created earlier.
with columns[1]:
st.markdown('#### Total Population Distribution')
choropleth = create_choropleth(year_data, 'states_code', 'population', chosen_palette)
st.plotly_chart(choropleth, use_container_width=True)
heat_map = create_heat_map(population_data, 'year', 'states', 'population', chosen_palette)
st.altair_chart(heat_map, use_container_width=True)
Third Column
The third column displays the top states, with the population shown as a colored progress bar. An about section is also added below it.
with columns[2]:
st.markdown('#### State Rankings')
st.dataframe(sorted_year_data,
column_order=("states", "population"),
hide_index=True,
width=None,
column_config={
"states": st.column_config.TextColumn(
"State",
),
"population": st.column_config.ProgressColumn(
"Population",
format="%f",
min_value=0,
max_value=max(sorted_year_data.population),
)}
)
with st.expander('Information', expanded=True):
st.write('''
- Data Source: [U.S. Census Bureau](https://www.census.gov/data/datasets/time-series/demo/popest/2010s-state-total.html)
- :blue[**Population Changes**]: States with significant population increase/decrease for the selected year
- :blue[**Migration Trends**]: Percentage of states with annual population change exceeding 50,000
- Developed with Streamlit
''')
Running the Application
To run the application is very easy, go to your terminal and navigate to the project folder/directory. Run this command:
Streamlit run your_app_name.py
The app will run and open in your browser port 8501 (http://localhost:8501/)

Deploy Your App
After you have successfully built your application, you can deploy it following the steps below:
- Publish your app in a public GitHub repository and ensure it has a requirements.txt file
- Sign in to share.streamlit.io and connect your GitHub
- Click on the Deploy an app and then paste in your GitHub URL
- Click on Deploy, and your app will be deployed on the Streamlit Community Cloud within minutes
- Copy your deployed app link and share it with the world
Conclusion
We have come to the end of this article, and as you can see, interactive data applications are on a whole new level, bringing more interaction and understanding to data applications. They are interestingly engaging, and they capture the audience.
The more interactivity you add to your data science application, the better your users understand the value you transmit to them.
For further study, check out these helpful resources:
Shittu Olumide is a software engineer and technical writer passionate about leveraging cutting-edge technologies to craft compelling narratives, with a keen eye for detail and a knack for simplifying complex concepts. You can also find Shittu on Twitter.
Source Link
Support Techcratic
If you find value in Techcratic’s insights and articles, consider supporting us with Bitcoin. Your support helps me, as a solo operator, continue delivering high-quality content while managing all the technical aspects, from server maintenance to blog writing, future updates, and improvements. Support Innovation! Thank you.
Bitcoin Address:bc1qlszw7elx2qahjwvaryh0tkgg8y68enw30gpvge
Please verify this address before sending funds.Bitcoin QR Code
Simply scan the QR code below to support Techcratic.

Please read the Privacy and Security Disclaimer on how Techcratic handles your support.
Disclaimer: As an Amazon Associate, Techcratic may earn from qualifying purchases.



