






























































2024-10-26 13:26:00
www.nextplatform.com

It was only a few months ago when waferscale compute pioneer Cerebras Systems was bragging that a handful of its WSE-3 engines lashed together could run circles around Nvidia GPU instances based on Nvidia’s “Hopper” H100 GPUs when running the open source Llama 3.1 foundation model created by Meta Platforms.
And now, as always happens when software engineers finally catch up with hardware features, Cerebras is back bragging again saying that its performance advantage for inference is even larger when running the latest Llama 3.2 models. The jump in AI inference performance between August and October is a big one, at a factor of 3.5X, and it opens up the gap between Cerebras CS-3 systems running on premises or in clouds operated by Cerebras or its sugar-daddy partner, Group 42.
AI inference will be a much bigger and in many ways easier market to tackle than AI training is, which Nvidia pretty much has locked down anyway. If you are wondering why Cerebras waited so long to tackle the inference market, the answer is simple: The company and its backers wanted a big story to tell as they peddle the initial public offering for the company to Wall Street. AI training is a big expensive problem, but most organizations around the world are not going to have the resources to train their own models, and they will be looking for the highest performing and least costly inference on which to deploy their AI applications.
At the moment, based on Llama 3.2 70B benchmarks done by Artificial Analysis and public data for pricing on GPU instances on the public cloud, on specialized GPU clouds that often push performance higher, and on non-GPU systems from rivals Groq and SambaNova Systems, it sure looks like Cerebras is winning in the AI inference race.
In this round of inference benchmark comparisons, Cerebras has focused on the updates to its inference running only on the Llama 3.2 70B model, which as the name suggests has 70 billion parameters. With 70 billion parameters at 16-bit data resolution, you need 140 GB of memory just to load those parameters, and each WSE-3 engine has only 44 GB of on-chip SRAM memory, so it takes a little more than three WSE-3 engines and therefore four CS-3 system nodes just to load the parameters for the Llama 70B models and have some memory left over to run them. (We did a drilldown on the WSE-3 engine and the CS-3 system back in March.)
The CS-3 nodes are interconnected with the on-wafer fabric that is part of the CS-3 architecture and that is managed by its SwarmX networking stack. Each WSE-3 wafer is rated at 125 petaflops (driven by 900,000 tensor cores on the wafer), has 21 PB/sec of aggregate bandwidth across its 44 GB of SRAM blocks, and delivers 214 Pb/sec of aggregate bandwidth into the SwarmX network.
The kind of performance leaps that Cerebras is showing for AI inference usually take a year or two, but it is not at all uncommon. Nvidia’s GPU hardware and software give a good illustration of the principle. Speaking very generally, each new GPU generation since Pascal has delivered about 2X the performance for AI workloads just based on the hardware alone. And by the time the next generation of hardware comes around, the performance of the software stack has increased by 4X to 5X yielding an 8X to 10X increase in performance on the older iron. Then the software tweaking and tuning process begins again on the new hardware.
With the numbers that Cerebras is showing, however, Nvidia and is GPU partners had better get to tuning. Because they are getting whipped in terms of both performance and price. Let’s take a look at the numbers.
Here is where the performance stacks up for Llama 3.2 70B inference according to Artificial Analysis:

Back in August, Cerebras was pushing 450 tokens per second running Llama 3.1 70B, and in September it moved to 589 tokens with an early version of Llama 3.2 70B. With that tweaking and tuning, the software engineers at Cerebras were able to push that up to a whopping 2,100 tokens per second on the same four nodes of CS-3 interlinked that was used back in August. That is a factor of 4.7X improvement in software – what Nvidia does in two years.
Now, either the Cerebras software engineers were under-promising so they can over-deliver in the clinch – Mr Scott would be more than a wee bit proud – or they had a massive and unexpected breakthrough. Cerebras is not telling. But James Wang, director of product marketing at Cerebras and formerly a GeForce product manager at Nvidia, tells The Next Platform that this is probably the bulk of the performance increases we can expect on the CS-3 iron.
By the way, back in August, Cerebras was pushing 1,800 tokens per second running the Llama 3.1 8B model, so with whatever changes the company made to its inference stack, it can deliver 70B inference at greater than its former 8B speed, which should mean more accurate inferences at a 17 percent or so faster rate.
Importantly for Cerebras, its Llama 3.2 70B performance is 8X to 22X higher than eight-way HGX nodes using “Hopper” H100 GPUs out there on the various clouds running at only 3B parameter counts, according to the data culled from Artificial Analysis. Take a gander:
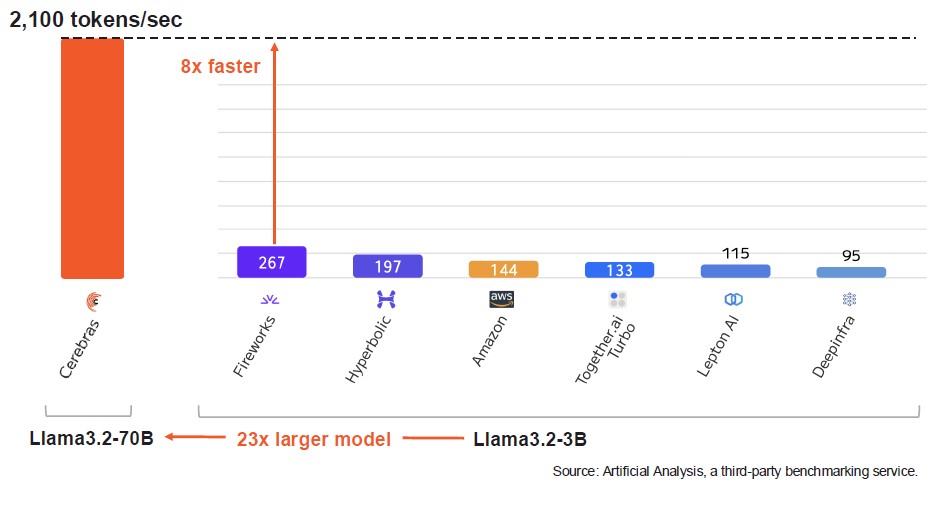
It would be interesting to see what the delta in accuracy is for these benchmarks. But Cerebras can run models that are 23.3X denser and do it anywhere from 8X to 22X faster – the average is 13.2X faster in the data shown above – and that is a multiplicative inference performance advantage of 308X by our math.
And if you compare Cerebras pricing per token on the cloud versus Nvidia Hopper GPU nodes on the cloud, Cerebras still has an advantage here, too:
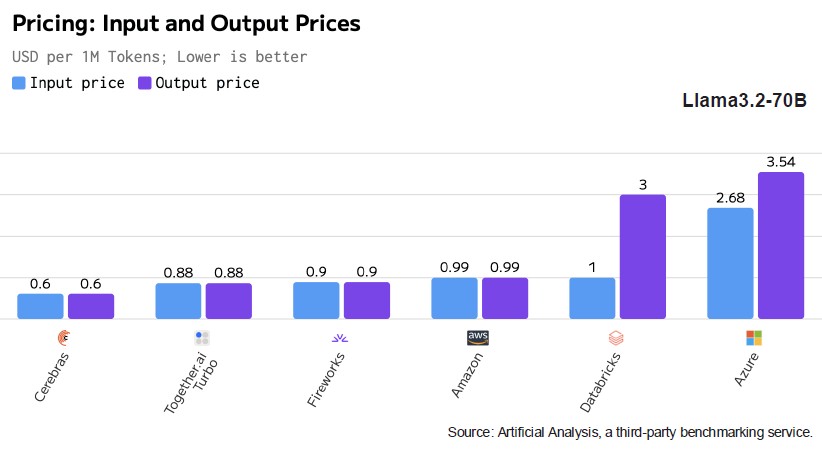
We have no idea if this pricing delta is reflected by those who are buying Nvidia Hopper systems and Cerebras CS-3 systems. So be careful. But we can do a little math to check.
As far as we know from the discussion of the Condor Galaxy supercomputer being installed at G42, 576 CS-3 nodes costs around $900 million, which is $1.56 million per node. An H100 HGX node with CPU hosts and main and flash memory and networking adapters probably costs around $375,000. That is $2,976 per token per second for the four CS-3 machines.
On the public clouds, which are not offering the highest performance on Llama 3.1 or 3.2 models, the price/performance is not that different. If you average out the performance of the cloudy instances in the performance chart above and use that as a gauge of Llama 3.2 70B inference performance, you get 45.9 tokens per second, and that works out to $8,170 per token per second.
So, the delta in price/performance between Cerebras and the Hoppers in the cloud when buying iron is 2.75X but for renting iron it is 5.2X, which seems to imply that Cerebras is taking a pretty big haircut when it rents out capacity. That kind of delta between renting out capacity and selling it is not a business model, it is a loss leader from a startup trying to make a point. But it remains to be seen if it will be sustainable. Cerebras will have to ramp up its sales and production to lower hardware acquisition costs to find out, and the only way to do that is to get lots of people interested and take the loss in the short term over a cloud.
All accelerator vendors except Nvidia and AMD are doing this same exact thing as they sell capacity in their clouds.
Betting on datacenter inference to drive the revenue stream at Cerebras – and indeed all of the AI startups – is easy. Inference is starting to look more and more like training, requiring more time to compute and more compute to do a better job inferring. This chart illustrates how chain of thought inference and agentic AI are going to drive much denser inference:
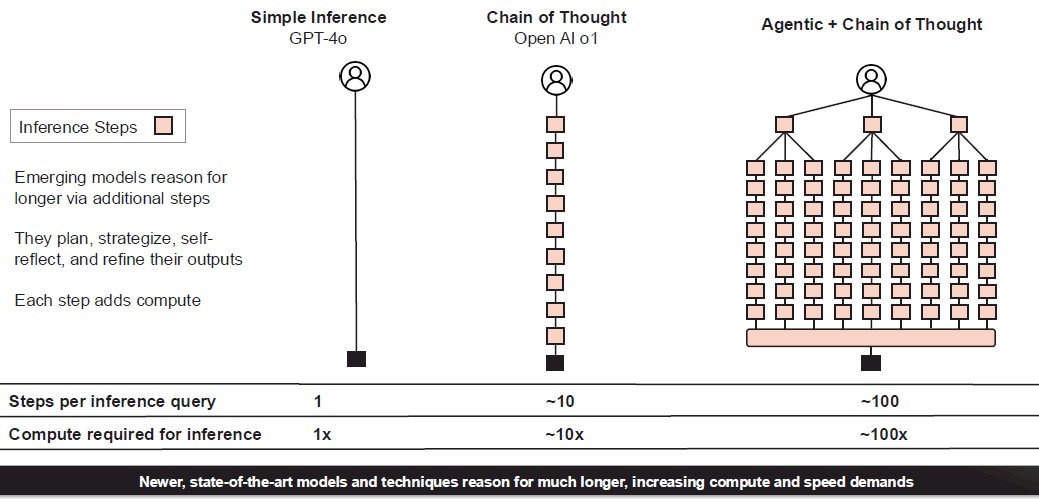
At 10X to 100X more compute to do inference, Cerebras could start getting enough volumes to drive the price down on its WSE-3 engines and CS-3 systems.
What we want to know, and what many prospective Cerebras customers want to know, is how the CS-3 systems will do running the Llama 3.2 405B model, which as the name suggests has 405 billion parameters and which has considerably more accuracy on inference tests than the 70B, 8B, and 3B models.
“We are completely not afraid of 405B,” Wang says. “In fact, we are bringing up 405B right now, and the meeting I just came from was about when do we bring this up and in what form. So you can absolutely state for the record that we are on the verge of releasing something in the 405B realm.”
By our math, it will take 810 GB of memory to load up the 405 billion parameters in this fat Llama 3.2 model, and that means it will take at least 18.4 WSE-3 engines to just load those parameters. Call it 20 engines for the sake of argument. That is a $31.25 million cluster, but at least you don’t have to use the MemoryX memory cluster that is really used for AI training, not inference. We wondered about the performance implications for interconnecting 20 CS-3 nodes to run such a large inference engine.
“We get this question a lot: If you’re running across multiple wafers, aren’t you bandwidth limited?” concedes Wang. “We split the model across layers to fit across these different wafers, and the internode bandwidth requirement is very modest –it is like 5 percent of our actual available hardware bandwidth. It is the tensor parallel stuff that really requires bandwidth. That’s why Nvidia has to do NVLink and NVSwitch, and for us, that piece works on our wafer fabric. So we are not afraid of the larger models. We are, in fact, looking forward to them. We do have to be a little bit efficient with memory so we don’t have to use too many systems.”
To our way of thinking, Cerebras needs a wafter of 3D vertical cache to expand the memory of its compute wafer like yesterday. We are absolutely convinced that the WSE-3 compute engine is mot compute bound, but is SRAM capacity bound. Instead of shrinking the wafer transistors to make the WSE-4, hopefully it can rework the dies on the wafer to have multiple stacks of SRAM underneath or on top of the dies, much as AMD does with 3D V-Cache (above) on its X variants of the Epyc CPUs and Infinity Cache (below) on the Instinct MI300X and MI300A GPUs. Ideally, each SRAM stack would deliver maybe an addition 60 GB of SRAM, and while we are dreaming here, why not have three or four stacks of SRAM? Assume that models will need a lot more memory capacity and bandwidth.
There is plenty of scale out already in the Cerebras architecture for AI training, but more SRAM might help training as well as inference.
With the CS-3 machines, there are options for 24 TB and 36 TB of MemoryX memory – a kind of cache for the on-wafer SRAM – for enterprise customers and 120 TB and 1,200 TB for hyperscalers and cloud builders, which provides 480 billion and 720 billion parameters of storage at the top end of the enterprise scale and 2.4 trillion or 24 trillion parameters for the hyperscalers and cloud builders. Importantly, all of this MemoryX memory can be scaled independently from the compute – something you cannot do with any GPUs or even Nvidia’s Grace-Hopper superchip hybrid, which has static memory configurations as well.

Support Techcratic
If you find value in Techcratic’s insights and articles, consider supporting us with Bitcoin. Your support helps me, as a solo operator, continue delivering high-quality content while managing all the technical aspects, from server maintenance to blog writing, future updates, and improvements. Support Innovation! Thank you.
Bitcoin Address:
bc1qlszw7elx2qahjwvaryh0tkgg8y68enw30gpvge
Please verify this address before sending funds.
Bitcoin QR Code
Simply scan the QR code below to support Techcratic.

Please read the Privacy and Security Disclaimer on how Techcratic handles your support.
Disclaimer: As an Amazon Associate, Techcratic may earn from qualifying purchases.



