

























































![Colony: Season One [DVD]](https://techcratic.com/wp-content/uploads/2024/11/91fkO93oDFL._SL1500_-360x180.jpg)


2024-11-14 21:21:00
nexa.ai
Omnivision is a compact, sub-billion (968M) multimodal model for processing both visual and text inputs, optimized for edge devices. Improved on LLaVA’s architecture, it features:
- 9x Tokens Reduction: Reduces image tokens from 729 to 81, cutting latency and computational cost.
- Enhanced Accuracy: Reduces hallucinations using DPO training from trustworthy data.
Demo
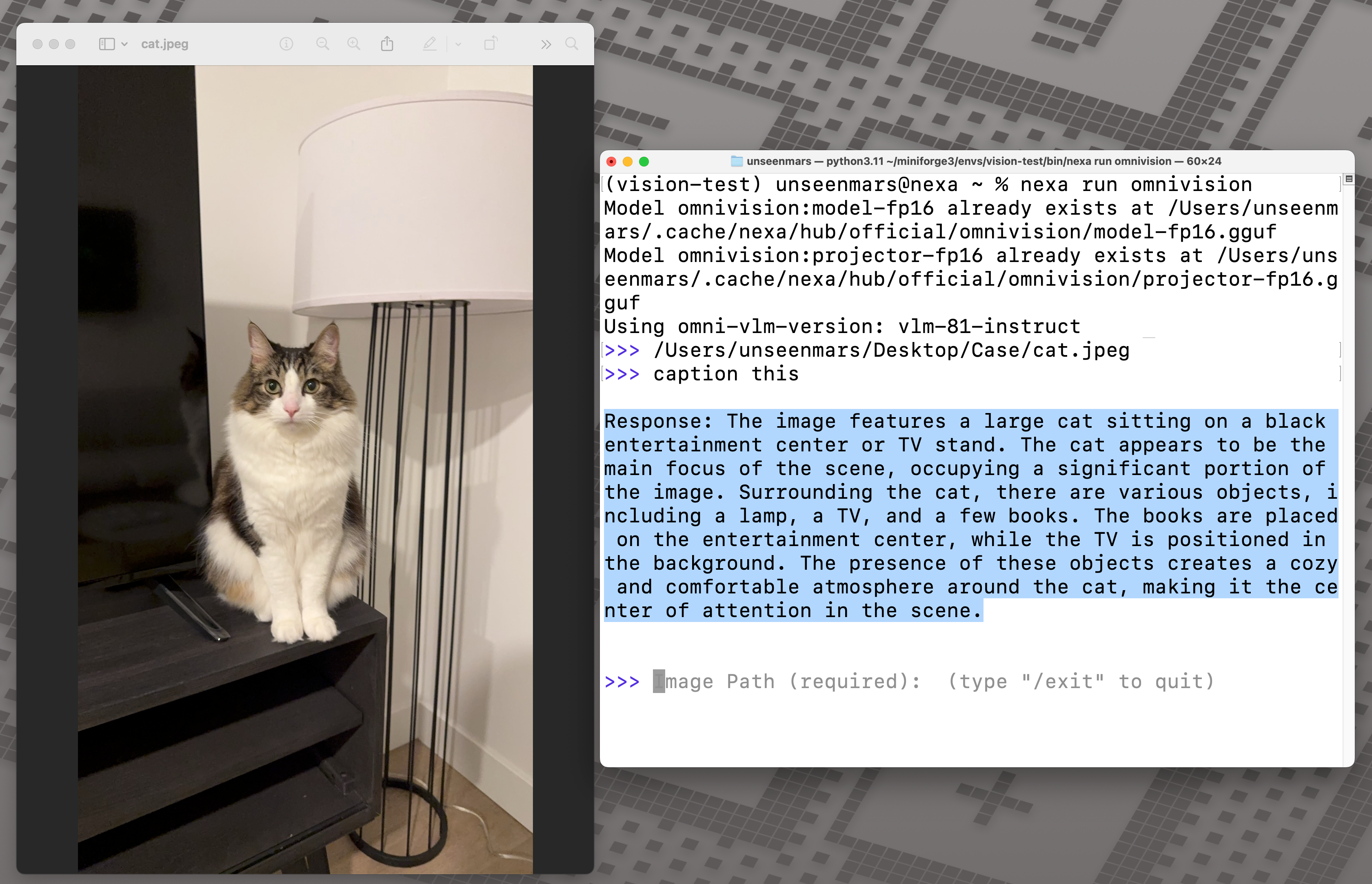
(OmniVision generated description for an image with multiple object)
(OmniVision generated description for an abstract art piece by Yayoi Kusama)
Get your hands on OmniVision
HuggingFace Space 🤗
Run OmniVision on Your Device
Install Nexa SDK, run this on your terminal:
Or run it with Streamlit local UI:
💻 OmniVision FP16 version requires 988 MB RAM and 948 MB storage space.
Model Architecture
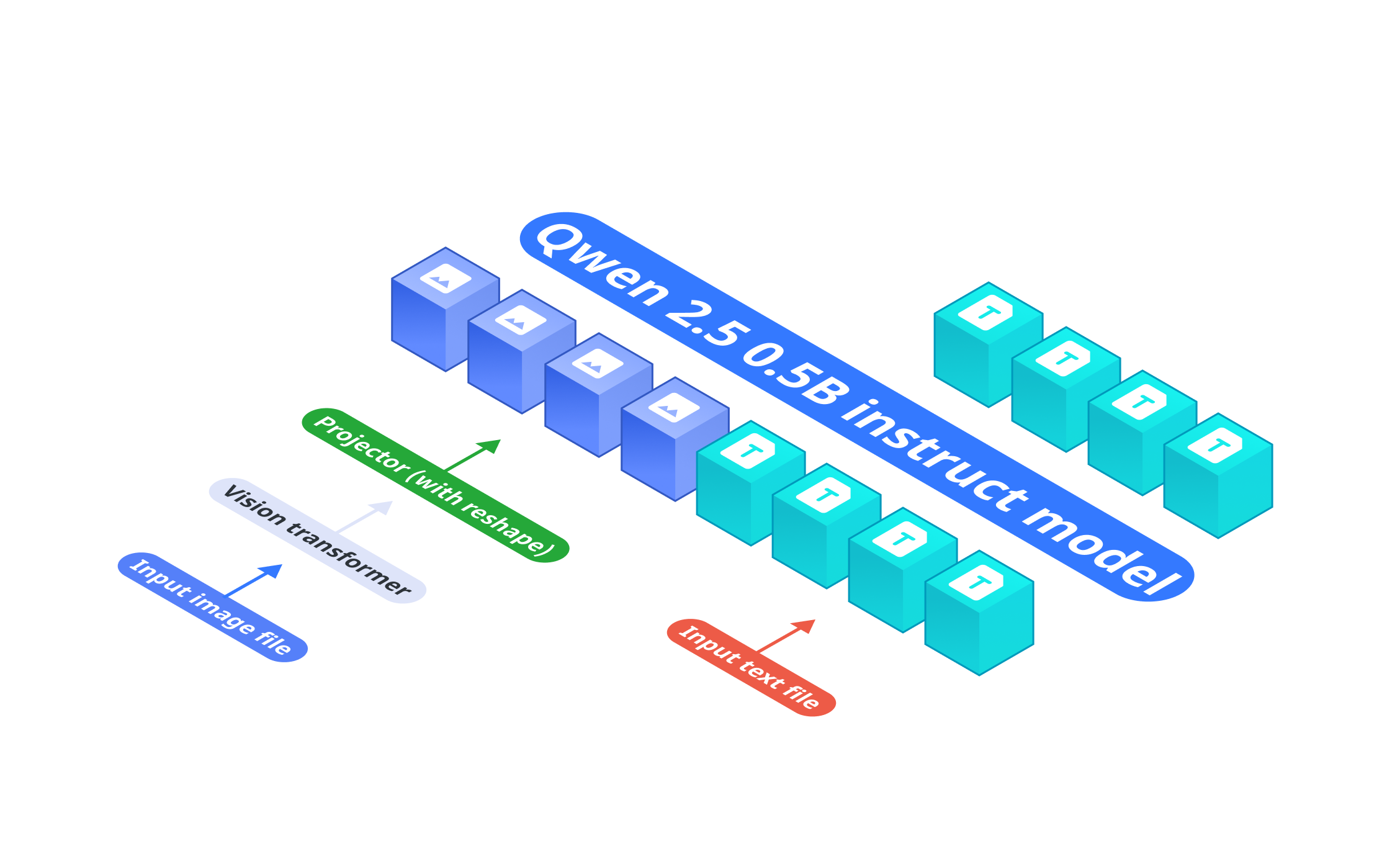
OmniVision’s architecture consists of three key components:
- Base Language Model: Qwen2.5-0.5B-Instruct functions as the base model to process text inputs.
- Vision Encoder: SigLIP-400M operates at 384 resolution with 14×14 patch size to generate image embeddings.
- Projection Layer: Multi-Layer Perceptron (MLP) aligns the vision encoder’s embeddings with the language model’s token space. Compared to vanilla Llava architecture, we designed a projector that reduce 9X image tokens.
The vision encoder first transforms input images into embeddings, which are then processed by the projection layer to match the token space of Qwen2.5-0.5B-Instruct, enabling end-to-end visual-language understanding.
Training Methodology
We developed OmniVision through a three-stage training pipeline:
Pretraining
The initial stage focuses on establishing basic visual-linguistic alignments using image-caption pairs, during which only the projection layer parameters are unfrozen to learn these fundamental relationships.
Supervised Fine-tuning (SFT)
We enhance the model’s contextual understanding using image-based question-answering datasets. This stage involves training on structured chat histories that incorporate images for the model to generate more contextually appropriate responses.
Direct Preference Optimization (DPO)
The final stage implements DPO by first generating responses to images using the base model. A teacher model then produces minimally edited corrections while maintaining high semantic similarity with the original responses, focusing specifically on accuracy-critical elements. These original and corrected outputs form chosen-rejected pairs. The fine-tuning targeted at essential model output improvements without altering the model’s core response characteristics.
Technical Innovations for Edge Deployment
9x Tokens Reduction through Token Compression
Processing image tokens creates significant computational overhead in edge deployment of multimodal models. In the standard LLaVA architecture, each image generates 729 tokens (27×27), leading to high latency and computational costs. We developed a reshaping mechanism in the projection stage that transforms image embeddings from [batch_size, 729, hidden_size] to [batch_size, 81, hidden_size*9]. This reduces token count by 9x without compromising model performance.Our experiments show this compression method hugely improved model performance. Analysis suggests this improvement stems from the base Qwen model’s handling of shorter sequences, where the compressed format provides more concentrated information representation.
Minimal-Edit DPO for Enhanced Response Quality
Traditional DPO methods can lead to significant shifts in model behavior. Our DPO implementation uses minimal-edit pairs for training. The teacher model makes small, targeted improvements to the base model’s outputs while preserving their original structure. This approach ensures precise quality improvements without disrupting the model’s core capabilities.
Benchmark
Below we demonstrate a figure to show how OmniVision performs against nanoLLAVA:
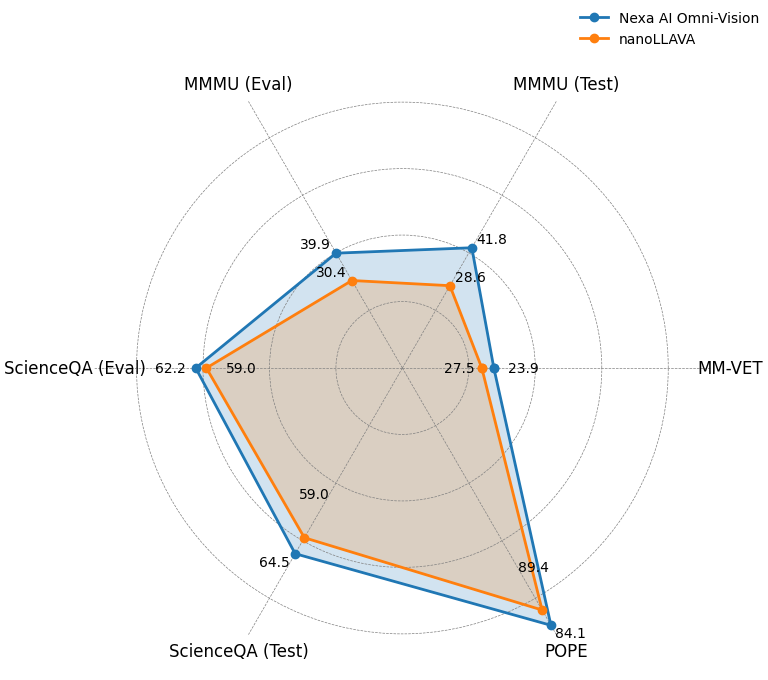
We have also conducted a series of experiments on benchmark datasets, including MM-VET, ChartQA, MMMU, ScienceQA, POPE to evaluate the performance of Omnivision.
|
Nexa AI Omni-Vision |
nanoLLAVA |
Qwen2-VL-2B |
|
|---|---|---|---|
|
MM-VET |
27.5 |
23.9 |
49.5 |
|
ChartQA (Test) |
59.2 |
N/A |
73.5 |
|
MMMU (Test) |
41.8 |
28.6 |
41.1 |
|
MMMU (Eval) |
39.9 |
30.4 |
41.1 |
|
ScienceQA (Eval) |
62.2 |
59.0 |
N/A |
|
ScienceQA (Test) |
64.5 |
59.0 |
N/A |
|
POPE |
89.4 |
84.1 |
N/A |
In all the tasks, OmniVision outperforms nanoLLAVA, the previous world’s smallest vision-language model.
What’s Next
Omnivision is in early development and we are working to address current limitations:
- Expand DPO Training: Increase the scope of DPO (Direct Preference Optimization) training in an iterative process to continually improve model performance and response quality.
- Improve document and text understanding.
In the long term, we aim to develop OmniVision as a fully optimized, production-ready solution for edge AI multimodal applications.

Kudos to
Blog written by
Support Techcratic
If you find value in Techcratic’s insights and articles, consider supporting us with Bitcoin. Your support helps me, as a solo operator, continue delivering high-quality content while managing all the technical aspects, from server maintenance to blog writing, future updates, and improvements. Support Innovation! Thank you.
Bitcoin Address:
bc1qlszw7elx2qahjwvaryh0tkgg8y68enw30gpvge
Please verify this address before sending funds.
Bitcoin QR Code
Simply scan the QR code below to support Techcratic.

Please read the Privacy and Security Disclaimer on how Techcratic handles your support.
Disclaimer: As an Amazon Associate, Techcratic may earn from qualifying purchases.





