Reward models have been a key part of reinforcement learning on top of LLMs, used broadly in techniques like RLHF and as LLM-as-a-judge critics in evals. They have also been used in the data preparation phase of preference optimization methods like SimPO, where a reward model was used to create the preference data used to train models like princeton-nlp/gemma-2-9b-it-SimPO.
I recently had some trouble figuring out how to run high throughput reward model inference. Offline, you can just collect everything you need to score in advance and go through all of your data in batches. But for a lot of use cases, such as for search methods like tree search or MCTS, this is hard to do efficiently. Unfortunately, easy to set up inference servers like vllm and llama.cpp don’t support sequence classification models1 out of the box (yet2)
Dynamic batching with batched
Thankfully, Mixedbread has a great generic dynamic batching library that makes it really easy to inference reward models3.
Here’s how we can host an endpoint on Modal4. First, let’s add some helper functions and setup the image:
from typing import List, Dict
import modal
image = modal.Image.debian_slim().pip_install([
"torch", "transformers", "accelerate", "batched", "hf_transfer"
]).env({"HF_HUB_ENABLE_HF_TRANSFER": "1"})
app = modal.App("reward-api", image=image)
MODEL_NAME = "RLHFlow/ArmoRM-Llama3-8B-v0.1"
with image.imports():
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
from batched import inference
def validate_messages(messages: List[Dict[str, str]]):
if not messages or len(messages) 2:
raise ValueError("Messages must contain at least a user and assistant message")
if not all(isinstance(m, dict) and 'role' in m and 'content' in m for m in messages):
raise ValueError("Each message must have 'role' and 'content' fields")
class RewardModelHelper:
def __init__(self, model):
self.model = model
@inference.dynamically(batch_size=8, timeout_ms=100.0)
def score_batch(self, features: dict[str, torch.Tensor]) -> torch.Tensor:
with torch.no_grad():
# Move input to same device as model
inputs = {k: v.to(self.model.device) for k, v in features.items()}
return self.model(inputs["input_ids"]).score.float()
from typing import List, Dict
import modal
image = modal.Image.debian_slim().pip_install([
"torch", "transformers", "accelerate", "batched", "hf_transfer"
]).env({"HF_HUB_ENABLE_HF_TRANSFER": "1"})
app = modal.App("reward-api", image=image)
MODEL_NAME = "RLHFlow/ArmoRM-Llama3-8B-v0.1"
with image.imports():
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
from batched import inference
def validate_messages(messages: List[Dict[str, str]]):
if not messages or len(messages) 2:
raise ValueError("Messages must contain at least a user and assistant message")
if not all(isinstance(m, dict) and 'role' in m and 'content' in m for m in messages):
raise ValueError("Each message must have 'role' and 'content' fields")
class RewardModelHelper:
def __init__(self, model):
self.model = model
@inference.dynamically(batch_size=8, timeout_ms=100.0)
def score_batch(self, features: dict[str, torch.Tensor]) -> torch.Tensor:
with torch.no_grad():
# Move input to same device as model
inputs = {k: v.to(self.model.device) for k, v in features.items()}
return self.model(inputs["input_ids"]).score.float()
I’m using RLHFlow/ArmoRM-Llama3-8B-v0.1, the same reward model used by the SimPO team, which uses Mixture-of-Experts aggregation of reward objectives with each expert corresponding to a human-interpretable objective (such as helpfulness, safety, coherence…)
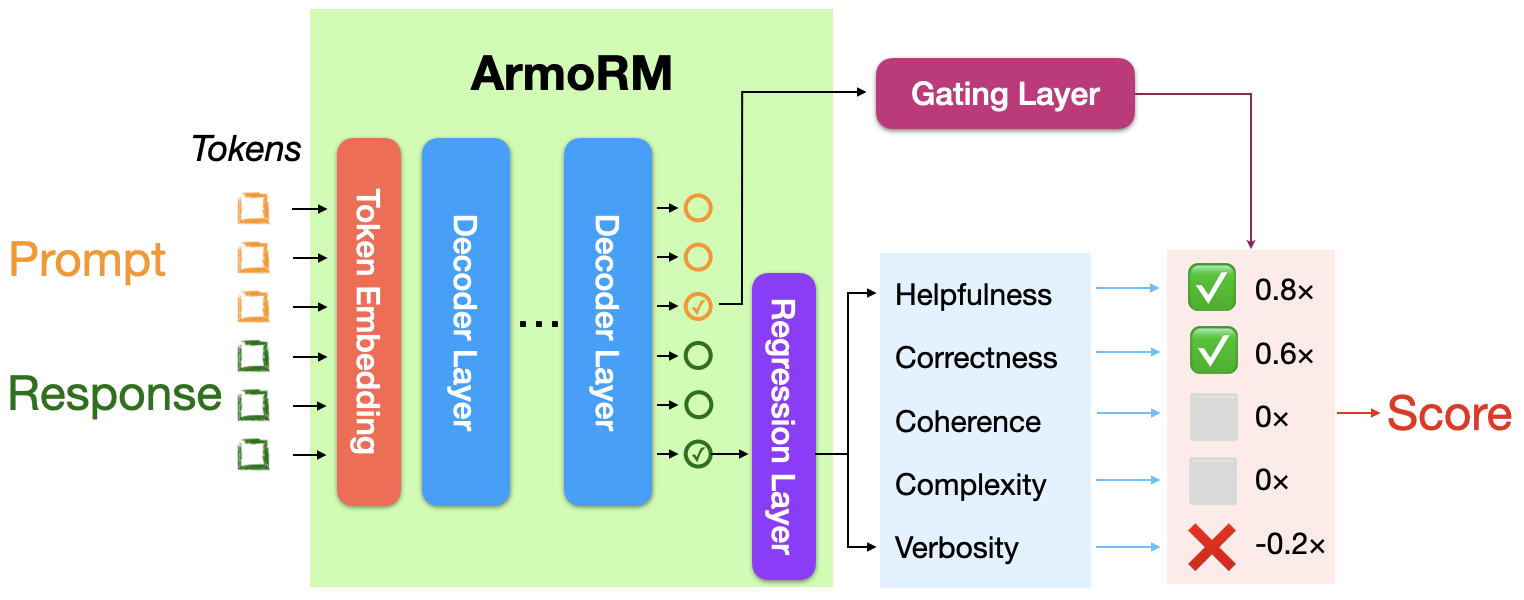
Check out the blog post from RLHFlow for more details5.
Now we can add the meat of the code, a web endpoint to score a LLM completion using dynamic batching under the hood.
@app.cls(
gpu=modal.gpu.A10G(),
allow_concurrent_inputs=1000,
container_idle_timeout=120,
)
class Model:
def load_model(self):
model = AutoModelForSequenceClassification.from_pretrained(
MODEL_NAME,
device_map="cuda",
trust_remote_code=True,
torch_dtype=torch.bfloat16,
use_safetensors=True,
)
return model
@modal.build()
def build(self):
self.load_model()
@modal.enter()
def setup(self):
self.model = self.load_model()
self.tokenizer = AutoTokenizer.from_pretrained(
MODEL_NAME,
use_fast=True,
)
self.score_batch = RewardModelHelper(self.model).score_batch
@modal.web_endpoint(method="POST")
async def score(self, messages_dict: Dict[str, List[Dict[str, str]]]):
messages = messages_dict["messages"]
validate_messages(messages)
inputs = self.tokenizer.apply_chat_template(
messages,
return_tensors="pt",
padding=True,
truncation=True,
)
score = await self.score_batch.acall({"input_ids": inputs})
return {"score": score[0].item()}
@app.cls(
gpu=modal.gpu.A10G(),
allow_concurrent_inputs=1000,
container_idle_timeout=120,
)
class Model:
def load_model(self):
model = AutoModelForSequenceClassification.from_pretrained(
MODEL_NAME,
device_map="cuda",
trust_remote_code=True,
torch_dtype=torch.bfloat16,
use_safetensors=True,
)
return model
@modal.build()
def build(self):
self.load_model()
@modal.enter()
def setup(self):
self.model = self.load_model()
self.tokenizer = AutoTokenizer.from_pretrained(
MODEL_NAME,
use_fast=True,
)
self.score_batch = RewardModelHelper(self.model).score_batch
@modal.web_endpoint(method="POST")
async def score(self, messages_dict: Dict[str, List[Dict[str, str]]]):
messages = messages_dict["messages"]
validate_messages(messages)
inputs = self.tokenizer.apply_chat_template(
messages,
return_tensors="pt",
padding=True,
truncation=True,
)
score = await self.score_batch.acall({"input_ids": inputs})
return {"score": score[0].item()}
The allow_concurrent_inputs setting prevents Modal from starting multiple servers so we can take advantage of dynamic batching. Now we can use this reward model endpoint with a hosted API or an open source model + vLLM.
Evaluating the reward model
Since my cloud GPU bill this month is kind of ridiculous, I decided to evaluate using a small random 100 question subset of TruthfulQA, a multiple choice benchmark for LLMs.
One way to benchmark the reward model on multiple choice data is to check the score for each possible answer to the question6. Here are the results:
Average rank of correct answer: 2.10
Times correct answer ranked first: 53/100
Average score difference from best: 0.0163
Average correct answer score: 0.0659
Average best score: 0.0821
Average rank of correct answer: 2.10
Times correct answer ranked first: 53/100
Average score difference from best: 0.0163
Average correct answer score: 0.0659
Average best score: 0.0821
The reward model scores the correct answer the highest 53% of the time. Next we will evaluate Best-of-N sampling, choosing the best LLM completion using the reward model.
Best-of-N-Sampling
Now we can test LLM + reward model verifier, a super simple way to add more test time compute. Best-of-N-Sampling doesn’t add much latency (we can sample and score hundreds of completions in parallel with batching) and is super easy to implement7.
I get the following zero-shot accuracy with Llama-3.1-8B-Instruct:
| # completions |
1 |
2 |
4 |
8 |
16 |
32 |
64 |
| accuracy (%) |
58 |
63 |
64 |
63 |
70 |
67 |
67 |
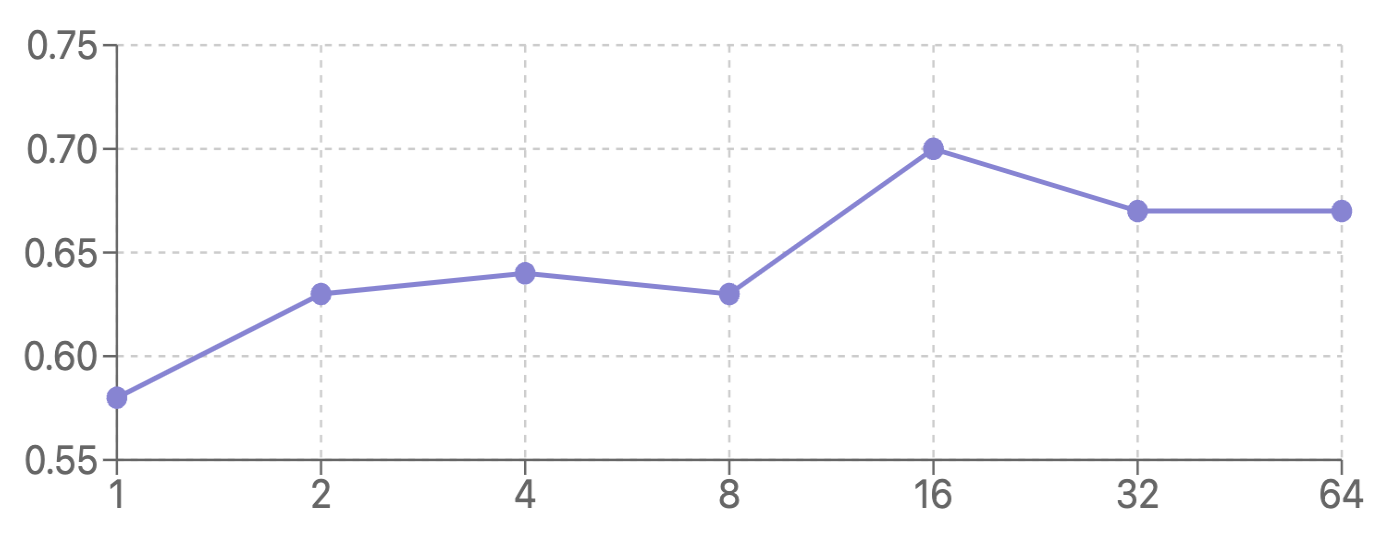
Using the reward model with Best-of-N-Sampling shows a 20.7% increase in accuracy from n=1 to n=16, with performance plateauing with more than 16 generations.
Support Techcratic
If you find value in Techcratic’s insights and articles, consider supporting us with Bitcoin. Your support helps me, as a solo operator, continue delivering high-quality content while managing all the technical aspects, from server maintenance to blog writing, future updates, and improvements. Support Innovation! Thank you.
Bitcoin Address:
bc1qlszw7elx2qahjwvaryh0tkgg8y68enw30gpvge
Please verify this address before sending funds.
Bitcoin QR Code
Simply scan the QR code below to support Techcratic.

Please read the Privacy and Security Disclaimer on how Techcratic handles your support.
Disclaimer: As an Amazon Associate, Techcratic may earn from qualifying purchases.




































































