









































![Gaming with Tomomi / GOOD ENDING – Roblox | [Full Walkthrough]](https://techcratic.com/wp-content/uploads/2024/11/1732207218_maxresdefault-360x180.jpg)













![Alien 3 [Blu-ray]](https://techcratic.com/wp-content/uploads/2024/11/91YlnAd8ibL._SL1500_-360x180.jpg)






2024-11-21 12:23:00
www.thenile.dev
When we need to describe Nile in a single sentence, we say “PostgreSQL re-engineered for multi-tenant apps”. By multi-tenant apps, we mean applications like Stripe, Figma, Twilio, Notion, Workday, and Gusto – here a large number of customers is served from a shared application stack. In these types of applications, a key architectural challenge is deciding how to store data for each customer.
What makes this data architecture especially challenging is the tension between two opposing needs. On one hand, requirements like latency, compliance, and scalability often push toward placing tenants on multiple databases. On the other hand, a single database offers a significantly better developer experience and cost model. Broadly speaking, there are two main approaches.
The first is database per tenant (or sometimes schema per tenant:
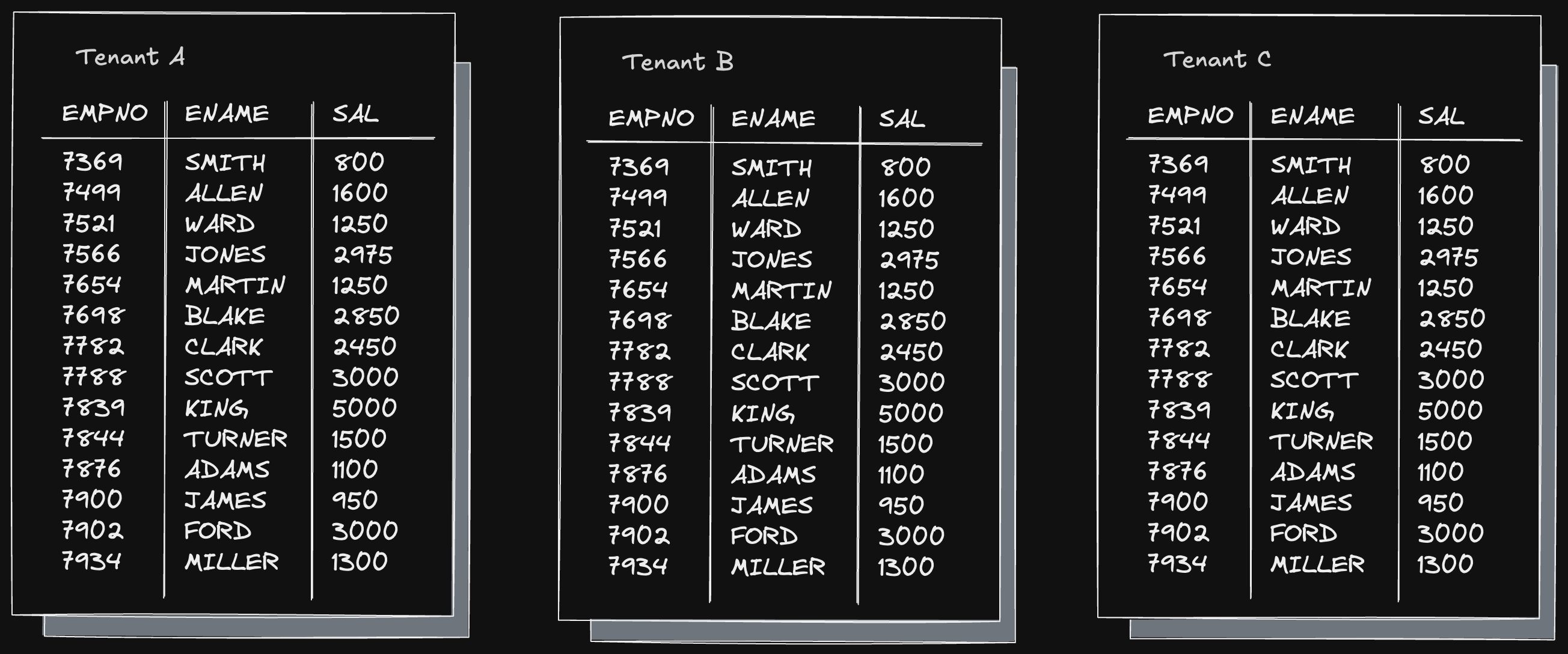
This architecture provides isolation and flexibility but requires more resources and effort to operate. The other approach is to place all tenants in the same shared schema and add a tenant identifier to every table:
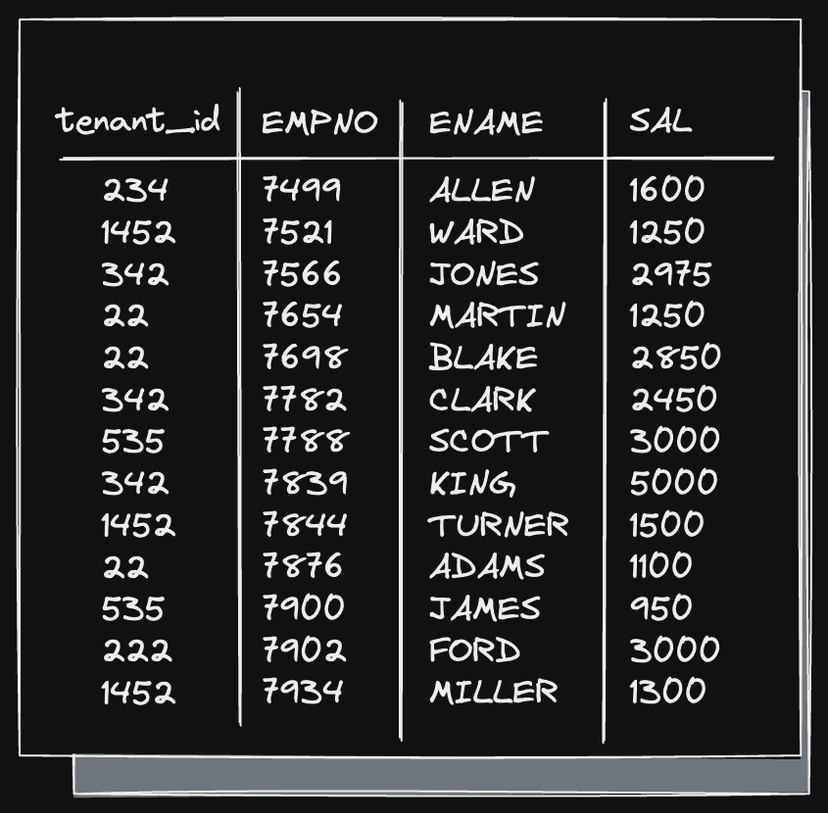
This approach is simple and cost-effective, which is why most new applications start here. However, over time, it can run into scalability issues and difficulties in adapting to individual customer needs and requirements.
That’s why, no matter where you start, you eventually end up with a hybrid model. In a typical hybrid architecture, the database is distributed out through sharding. Most tenants are placed on shared shards, while larger and more demanding customers are allocated dedicated shards.
Scale isn’t the only reason to use the hybrid architecture. A more common reason is the need to store data in multiple regions. Tenants always prefer low latency, which requires data to be placed close to them or in a specific region. Some tenants also have compliance concerns that requires storing their data in specific countries.
Both hybrid and db-per-tenant architectures require a way to propagate the DDL changes to all the tenants instantaneously with great devex and high reliability.
Nile provides all the developer experience, operational simplicity and cost benefits of a single database while also achieving the isolation and per-tenant control benefits of a db per tenant architecture.
The number of databases you need to build a multi-tenant app is one.
This one database contains many “virtual tenant databases” – one per tenant. These virtual tenant databases can be placed on multiple physical Postgres databases. Tenants can be placed on shared compute (which may be sharded depending on the workload), or on dedicated compute. Regardless of how the tenenant databases are organized, developers connect to one database and work as if everything were in a single shared schema.

Our goal is to support any number of virtual databases, distributed across a number of physical PostgreSQL instances, while still providing the seamless developer experience of a single schema shared by all tenants. DDLs (Data Definition Language commands) are SQL commands that modify the schema – things like CREATE TABLE, ALTER TABLE and DROP INDEX. Our goals for the developer experience with DDLs are:
- Each DDL applies to all tenants concurrently
- Behaves exactly as it normally would in Postgres. This includes supporting transactions with DDL and all the transactional guarantees (which we consider one of PostgreSQL’s best features). It also includes performing the DDL synchronously from the user point of view, when the
CREATE TABLEcommand returns, the table must be visible and usable for all tenants, regardless of their placement. - The fact that each DDL executes over multiple virtual databases and physical instances should be completely transparent to developers
To deliver on these requirements, Nile built pg_karnak. pg_karnak is a distributed ddl layer that operates across tenants and postgres instances. It includes an extension that intercepts ddls, a transaction coordinator to apply schemas to every tenant during DDL execution and a central metadata store. This ensures correct DDL application and enables recovery for tenants in case of failure.
In this blog, we’ll dive into the architecture and implementation of pg_karnak. We’ll start with a high-level overview of the architecture and walk you through the green-path flow of executing a simple DDL. Then we’ll dive into the details of how we solved the three most challenging problems with distributed DDLs: transactions, locks and failure handling. Along the way, we’ll share some tips and tricks we used in building our Postgres extension — these might come in handy if you decide to write your own extensions.
So, grab a coffee, and let’s get started!
Distributed DDL architecture walkthrough
We’ve implemented our distributed DDL system using two main components:
pg_karnakextension: This extension is loaded into every Postgres instance. It is responsible for intercepting DDL statements, extracting key information, and initiating the distributed transactions.- Transaction coordinator: This is a stand-alone service that distributes the DDL statements to all relevant databases and ensures that each DDL is either applied successfully to all databases or to none of them.
To understand how these components work together to execute a DDL statement, let’s look at what happens when a user connects to their Nile database and issues a CREATE TABLE command. This command is sent from the client to one of the Postgres instances, where it is intercepted by the pg_karnak extension.
Intercepting DDL with processUtility_hook
In order to intercept the DDL before it executes, pg_karnak uses the processUtility_hook. To understand why and how our extension uses this hook, we first need to explain what a utility command is and how PostgreSQL handles them.
In Postgres terms, a “utility” is any command except SELECT, INSERT, UPDATE and DELETE. This includes all DDL commands as well as other commands like COMMIT, NOTIFY or DO. When Postgres recieves a utility command, it uses ProcessUtility(..) method to process it. This is a simple wrapper that looks like this:
if (ProcessUtility_hook)
(*ProcessUtility_hook) (...);
else
standard_ProcessUtility(...);
This method checks if there are any extensions that want to process the utility command before Postgres runs its standard processing. The pg_karnak extension provides such a hook and, as a result, is called before Postgres processes any command. This is incredibly useful because processUtility_hook is triggered for nearly everything that isn’t a SELECT or a DML, giving us a single entry point for almost everything we need to handle.
Once we finished processing the command, it is our responsibility to call standard_ProcessUtility, so that Postgres can continue its normal flow. A bit off-topic, but in case you’re curious: standard_ProcessUtility method is essentially a gigantic switch statement that routes every one of the 60+ utility commands to their appropriate handler.
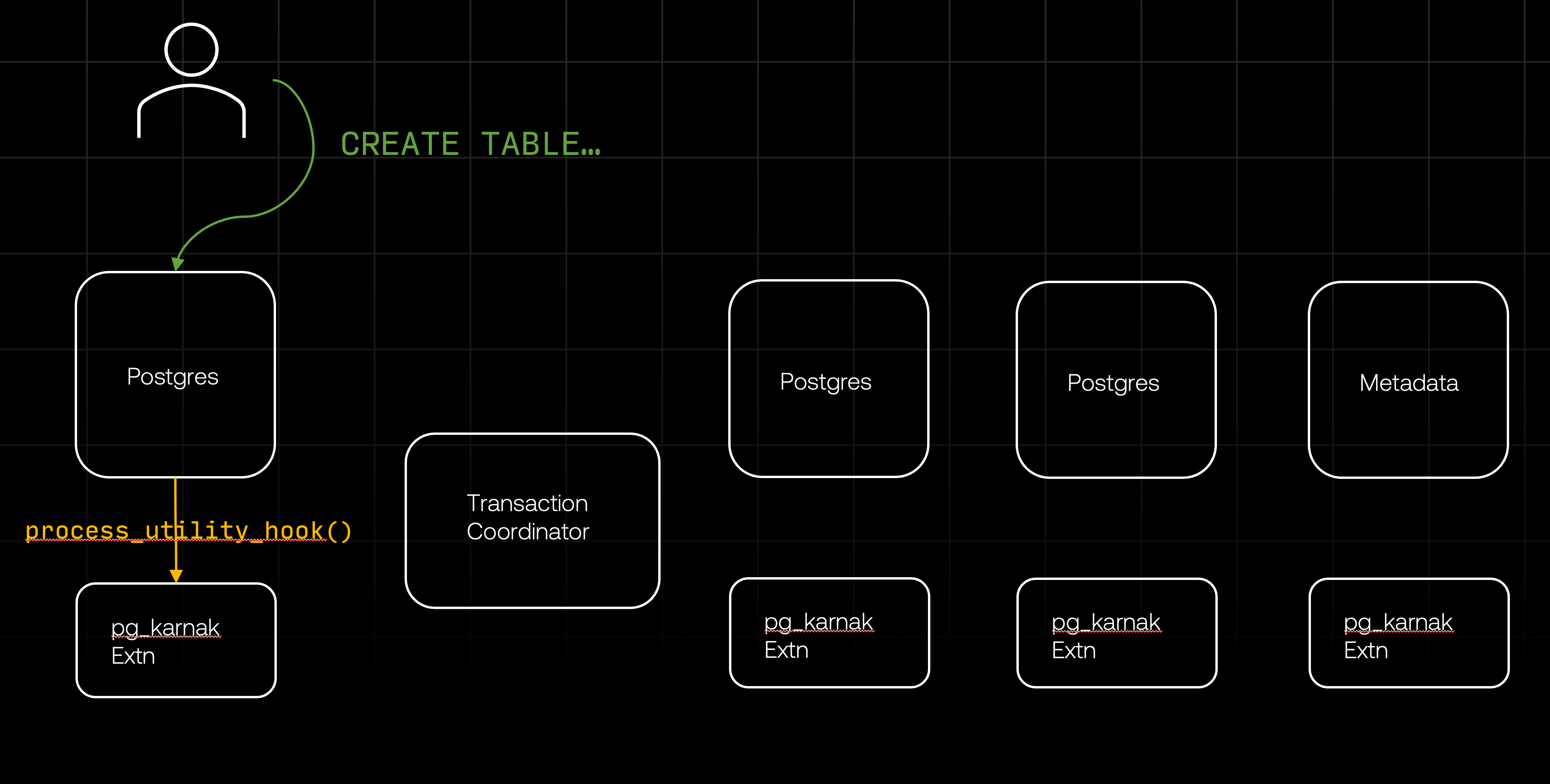
So, our extension gets called with a utility command. What happens next? At this point, it needs to perform a few tasks:
- Check that the command is one we want to handle There are many utility commands and we only handle a subset. Commands that we don’t handle, like
FETCH,SHOWorDISCARDare just passed directly tostandard_ProcessUtility. - Raise error for unsupported DDL. Nile has specific restrictions on the type of relations we allow. For example, primary keys must include the
tenant_idcolumn, andtablespacecommands are not supported at all (Nile handles these automatically). - Determine which locks the DDL requires.
- Begin a distributed transaction (only needed if this is the first DDL in a transaction)
- Ask the transaction coordinator to distribute the locks
The reason we extract the locks and distribute them early in the process is to minimize the time spent holding a lock and reduce the risk of lock conflict. Most DDL statements require an ACCESS EXCLUSIVE lock, which not only prevents any queries from accessing the table in question while the DDL is executing but also prevents any new queries from accessing the table while the DDL is waiting to acquire the lock. To minimize the risk and the time spent while holding the lock, Nile attempts to acquire the necessary locks – with a short lock timeout – on all relevant databases before starting to execute the DDLs. If the lock acquisition fails on any database, the DDL will return an error rather than continue waiting for the lock.
Acquiring locks with a short timeout before executing DDLs is considered a best practice in Postgres for the reasons we just explained. Nile’s distributed DDL implement this best practice for our users.
Transaction coordinator
Once the pg_karnak extension determines the necessary locks, it calls the transaction coordinator to start a transaction (if necessary) and distribute the locks.
Starting the transaction is straightforward: the coordinator maintains open connections to all databases and simply sends each one a BEGIN command.
Distributing the locks works similarly. The coordinator sends all databases the commands required to acquire the locks (more details in the section on locking). To avoid deadlocks, we ensure that locks are always acquired in the exact same order – both in terms of the sequence of databases and the order of locks within each database. This guarantees early failure in the event of conflicts and prevents situations where two concurrent transactions are each waiting for the other to release a lock on a different database.
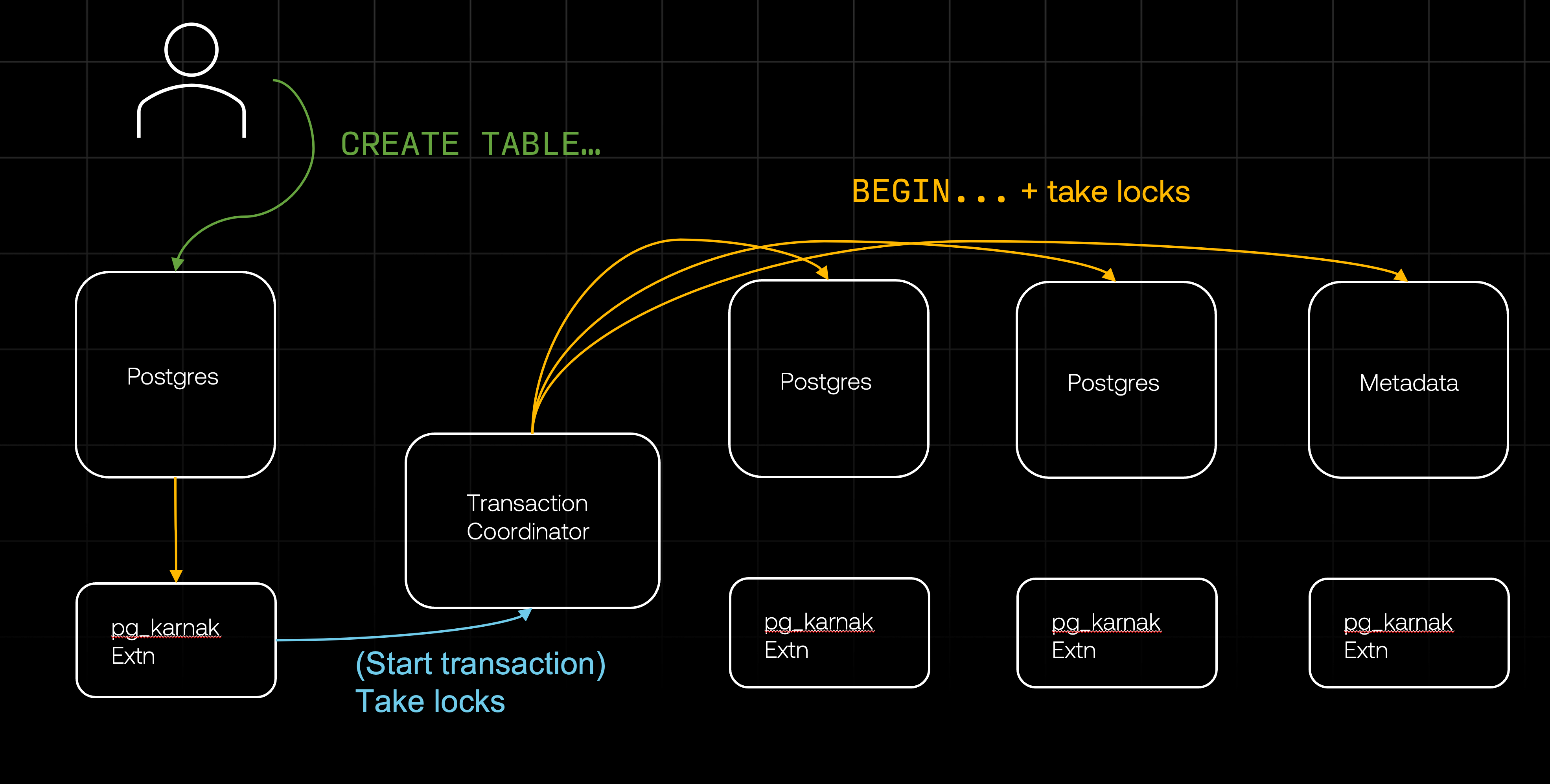
Once the locks are acquired, the pg_karnak extension instructs the coordinator to distribute the DDL itself. But first, it has to make sure the DDL is fully qualified. CREATE TABLE todos (...) can be ambigous – in which schema should Postgres create the table? This depends on the current search_path config and the existing schema, which can change on some databases while the DDL is distributed (for example, if there’s a concurrect CREATE SCHEMA operation). To avoid an inconsistent result, pg_karnak modifies the DDL and makes sure all objects are fully qualified. Only then it sends the DDL to the transaction coordinator for distribution.
While the coordinator sends the DDL command to all other databases, the original extension that first received the DDL proceeds to call standard_ProcessUtility and process the DDL locally.
Meanwhile, each remote database receives the DDL command. Since every database runs our extension, these DDL commands are intercepted by the extension on each database. It is crucial that the extension does not attempt to redistribute these DDLs, as doing so would lead to an infinite loop. Therefore, the extension has to recognize that these DDLs were sent by the transaction coordinator and can be passed directly to standard_ProcessUtility. To achieve this, we use a configuration (GUC) set when the transaction coordinator initializes the transaction. This configuration indicates to the extension that it doesn’t need to reprocess the DDLs that follow, as they have already been validated by the originating extension and distributed by the coordinator.
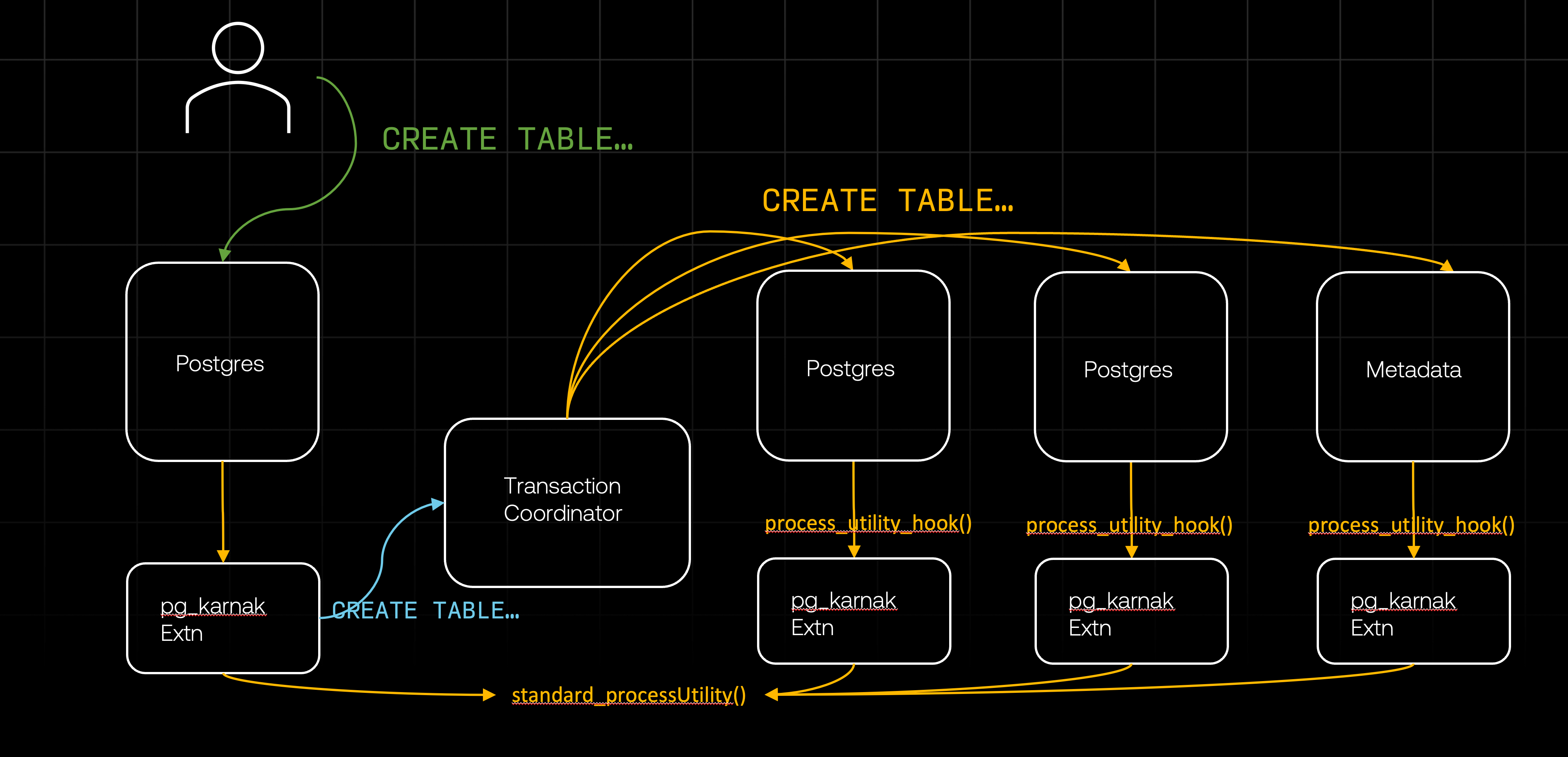
Once all the databases finished processing the DDL, the coordinator notifies the originating extension of successful completion. The extension, which has already finished processing the DDL locally, can return the response to the client. At this point, we have successfully executed a distributed DDL.
Or almost. We still need to commit the transaction. To maintain atomicity guarantees, it must commit on all databases or none at all. Let’s look in detail at how we commit the distributed transaction.
Transactions
You may recall from an earlier section that BEGIN, COMMIT, ABORT and ROLLBACK are all utility commands. So it might seem like we could handle transactions by having our processUtility_hook intercept these commands and implement distributed transactions. This approach is tempting, but it has some critical drawbacks:
- Intercepting every
BEGINwill be very costly in a transaction-heavy database. Most of this effort will be wasted, as an OLTP system processes billions of DML transactions for every DDL. - Transactions can be implicit – standalone DDL statements are treated as transactions, for example. We won’t always have a
BEGINto intercept, so we must treat each DDL as potentially starting a transaction. - Intercepting a
COMMITonly gives us a single point to intercept – when theCOMMITcommand is sent. However, distributed transactions require a two-phase commit, which can’t be implemented with this single hook.
Fortunately, PostgreSQL provides a better mechanism for extensions to hook into the transaction lifecycle: XactCallback (pronounced “transaction callback”).
This callback is triggered on various events within the transaction lifecycle, with an enum parameter that specifies which event occured. The events that we are interested in are:
XACT_EVENT_PRE_COMMIT– This event occurs just before the commit itself. The callback method is allowed to return an error while processing it. If an error is returned, Postgres will abort the transaction and force a rollback.XACT_EVENT_COMMIT– This event happens after the commit. At this point, the callback is not allowed to return an error. Regardless of what happened, it must reach a healthy and successful state since the client will recieve a confirmation that the transaction was successfully committed.XACT_EVENT_ABORT– This event is triggered when the transaction is aborted and the callback needs to handle the rollback.
The pg_karnak extension maps these events into a distributed two-phase commit (2PC) process.
The first task for the extension is to detect when to start a distributed transaction. This is simpler than it sounds: if processUtility_hook is called with a DDL and there’s no currently active transaction in the same session, then the extension tells the transaction coordinator to begin a transaction. There’s no scenario where a DDL is processed without an active transaction. If a transaction is already in progress for the session, the extension will continue to process all arriving DDLs.
This process continues until XactCallback is triggered with XACT_EVENT_PRE_COMMIT event, which indicates that Postgres is preparing to commit the transaction. This callback is triggered regardless of whether there is an explicit transaction with an explicit COMMIT or Postgres is committing an implicit transaction. The callback handles the pre-commit event by notifying the transaction coordinator and passing along the transaction ID.
The transaction coordinator then sends the PREPARE TRANSACTION command to all relevant databases.
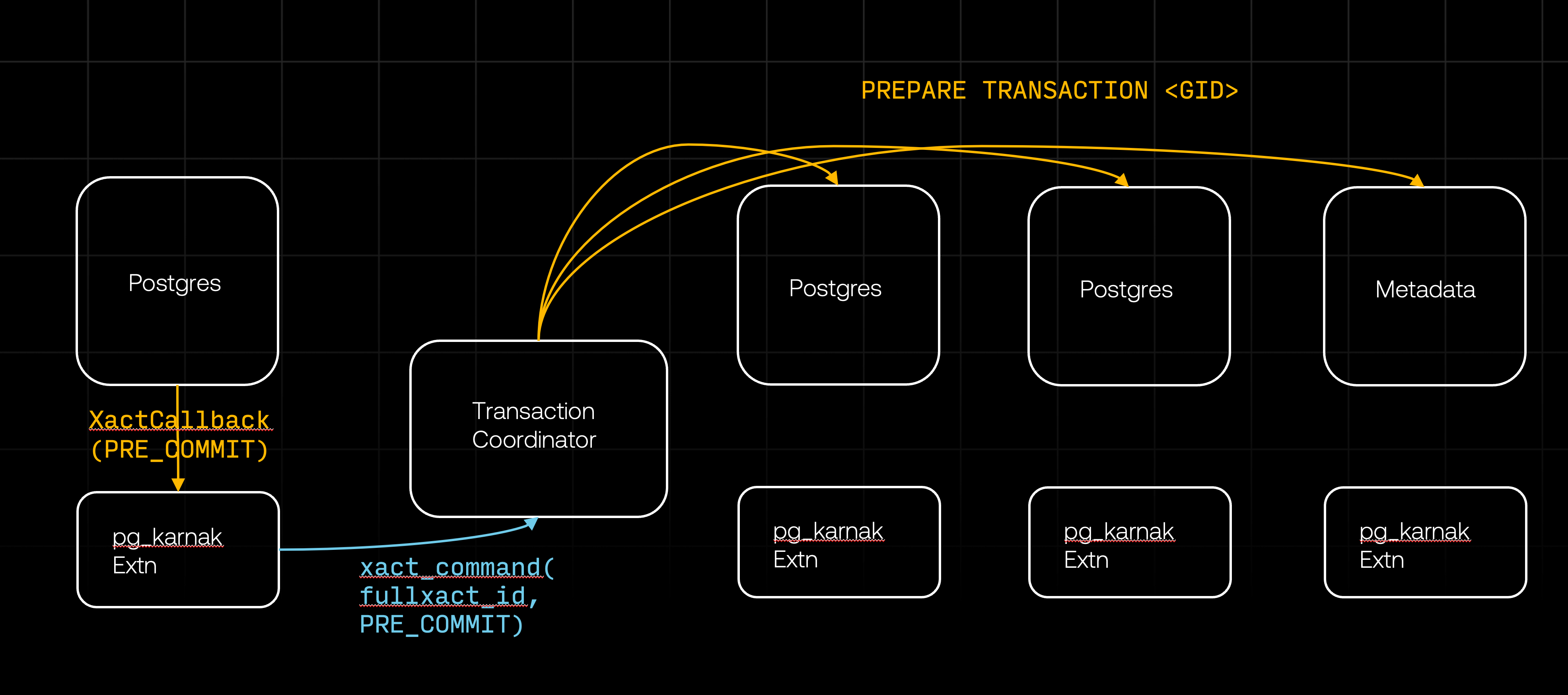
According to the Postgres documentation, the PREPARE TRANSACTION behaves as follows:
PREPARE TRANSACTIONprepares the current transaction for two-phase commit. After this command, the transaction is no longer associated with the current session; instead, its state is fully stored on disk, and there is a very high probability that it can be committed successfully, even if a database crash occurs before the commit is requested.
Once prepared, a transaction can later be committed or rolled back withCOMMIT PREPAREDorROLLBACK PREPARED, respectively. Those commands can be issued from any session, not only the one that executed the original transaction.
The phrase “very high probability that it can be committed successfully” may sound a bit less reassuring than we’d like. In practice, it means that PREPARE TRANSACTION is successful when it has persisted the transaction state to disk. The transaction will be committed successfully unless the database crashes and the files or disks where it is stored are completely lost. If this happens, it is likely that much more than just this one transaction is lost. In other scenarios, such as running out of memory, the “prepared” state is preserved and the transaction can be committed if COMMIT PREPARED is retried, even from other sessions.
Barring this very rare scenario, PREPARE TRANSACTION has all the properties we need from the first phase of two-phase commit: It is durable, and the prepared transaction can be committed or rolled back from any session. This ensures that once we successfully prepared transactions on all databases, we can reach a consistent state no matter what else happens. Additionally, if PREPARE TRANSACTION fails, it will automatically trigger a rollback on the database where it failed.
Let’s assume that all databases successfully prepared their transactions for commit (we’ll cover the failure scenarios in the next section). This succesful preparation completes the first phase of the two-phase commit (2PC). The XactCallback on the originating database will then return successfully, allowing Postgres to proceed with the transaction commit. The XactCallback will be triggered once more, this time with XACT_EVENT_COMMIT event. During this phase, the first action the pg_karnak extension takes is to reset its state – such as cleaning up the transaction in progress – so that the next DDL command will begin a new transaction. This cleanup comes first to simplify error handling. Then the extension commits the transaction locally and instructs the transaction coordinator to send the COMMIT PREPARED command to all databases, which commits all the prepared transactions in the remote databases.
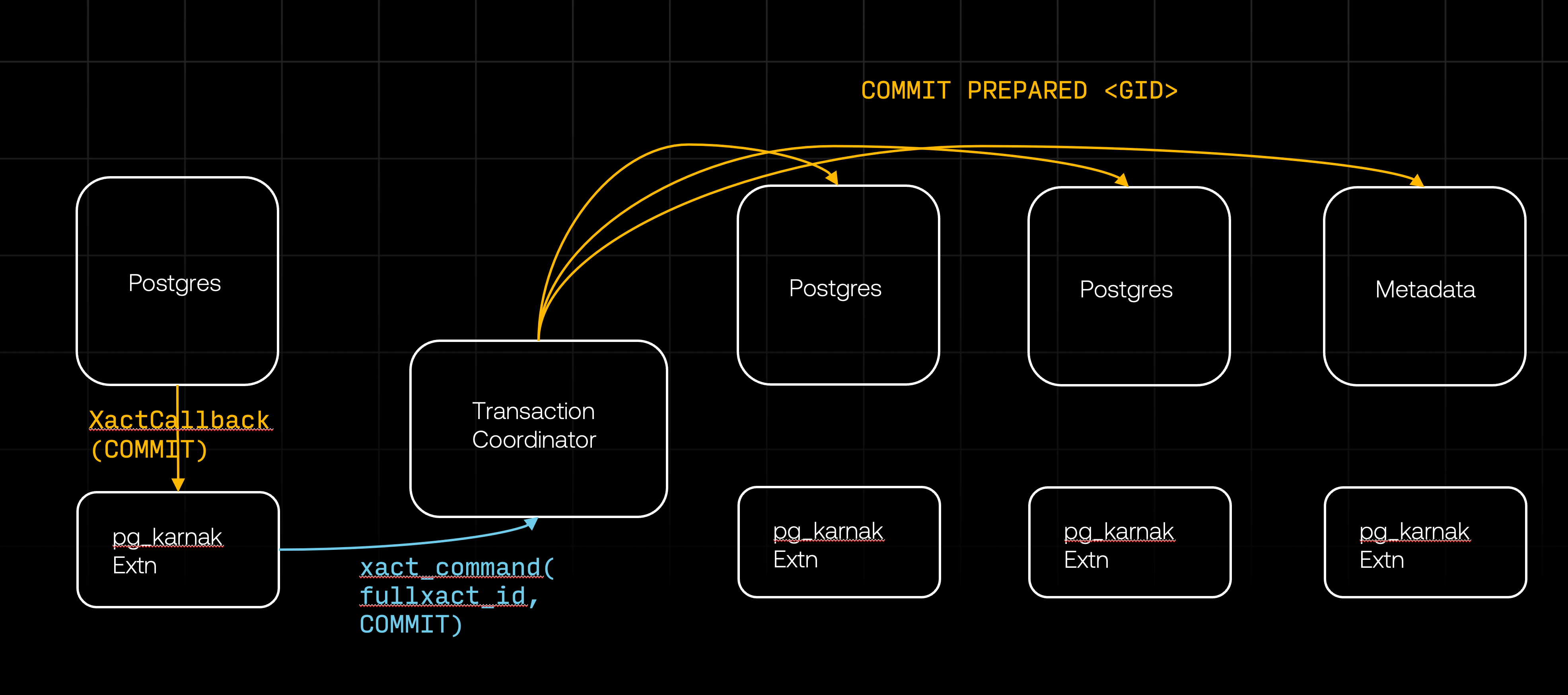
Once all the databases commit, the second phase of the 2PC is completed, and the distributed transaction is fully committed. We still need to discuss what happens if they don’t commit successfully. But before diving into that, lets take a quick detour and look at how we handle locks.
Locks
If you recall, the first step the pg_karnak extension takes toward distributing a DDL is to determining the locks the DDL will need and attempt to acquire them on all relevant databases. We approach this with 3 simple goals in mind:
- Fail early: If a DDL is going to fail due to inability to acquire locks, we want to detect this before performing any resource-intensive operations.
- Minimize blocking: Many DDLs require
ACCESS EXCLUSIVElock and attempts to acquire this lock will block other sessions, even while waiting. In a busy OLTP system, it is important to minimize such blocks. - Avoid deadlock: We want to prevent situations where two sessions are stuck waiting for each other to release a lock, resulting in neither making progress.
To fail early, we ensure all the necessary locks are acquired as the first step in processing a DDL, even before executing the DDL locally. While we could acquire locks in parallel, this approach could be wasteful – imagine building an index on a large table locally only to roll it back because we couldn’t acquire the lock on a table in one of the remote databases.
The pg_karnak extension determines the required locks by analyzing the DDL. ALTER and DROP are fairly straight forward: we acquire locks on the objects being modifying. DROP CASCADE may require identifying and locking all dependent objects. In most cases, acquiring the lock is simply a matter of sending LOCK TABLE

Keep your files stored safely and securely with the SanDisk 2TB Extreme Portable SSD. With over 69,505 ratings and an impressive 4.6 out of 5 stars, this product has been purchased over 8K+ times in the past month. At only $129.99, this Amazon’s Choice product is a must-have for secure file storage.
Help keep private content private with the included password protection featuring 256-bit AES hardware encryption. Order now for just $129.99 on Amazon!
Support Techcratic
If you find value in Techcratic’s insights and articles, consider supporting us with Bitcoin. Your support helps me, as a solo operator, continue delivering high-quality content while managing all the technical aspects, from server maintenance to blog writing, future updates, and improvements. Support Innovation! Thank you.
Bitcoin Address:
bc1qlszw7elx2qahjwvaryh0tkgg8y68enw30gpvge
Please verify this address before sending funds.
Bitcoin QR Code
Simply scan the QR code below to support Techcratic.

Please read the Privacy and Security Disclaimer on how Techcratic handles your support.
Disclaimer: As an Amazon Associate, Techcratic may earn from qualifying purchases.




