






























![Hogwarts Legacy Gameplay Walkthrough | Episode 16 Flying Class [2k 60 FPS]](https://techcratic.com/wp-content/uploads/2025/07/1752919673_maxresdefault.jpg)


![Scars Above [Gameplay, Part 1]](https://techcratic.com/wp-content/uploads/2025/07/1752899038_hqdefault.jpg)



















![F-16 Multirole Fighter [Online Game Code]](https://techcratic.com/wp-content/uploads/2025/07/A11QPks6vlL.png)


































2024-12-18 11:31:00
www.greptile.com
This post is adapted from a talk I gave at the Sourcegraph Dev Tools meetup at
the Cloudflare office in San Francisco on December 16th, 2024.
I am Daksh, co-founder of Greptile – AI that understands large codebases. Our most popular product is our AI code review bot. It does a first pass review of PRs with full context of the wider codebase, surfacing bugs, anti-patterns, repeated code, etc.
When we first launched this product, the biggest complaint by far was that the bot left too many comments. In a PR with 20 changes, it would leave as many as 10 comments, at which point the PR author would simply start ignoring all of them.
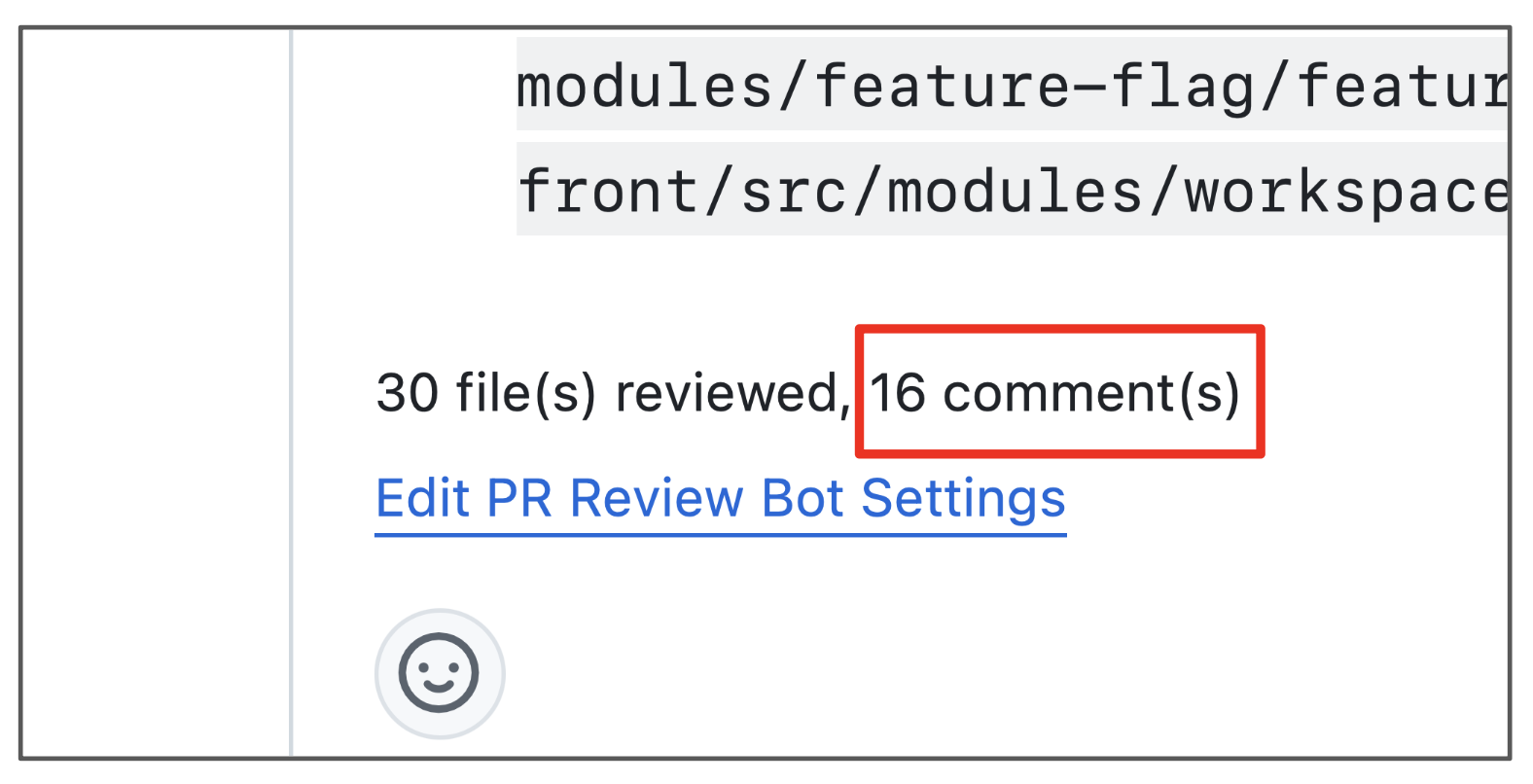
We needed to:
- figure out how to reduce the number of comments that Greptile was generating,
- which meant figuring out which comments should be eliminated,
- which meant figuring out a way to evaluate the quality of each comment.
There were two ideas here:
- GitHub lets developers react to comments with 👍/👎. We could use this as the quality indicator.
- We could check which comments the author actually addressed in the code by scanning the diffs of the subsequent commits.
We picked the latter, which also gave us our performance metric – percentage of generated comments that the author actually addresses.
We analyzed existing Greptile comments and found that ~19% were good, 2% were flat-out incorrect, and 79% were nits – comments that were technically true but not something the dev cared about.
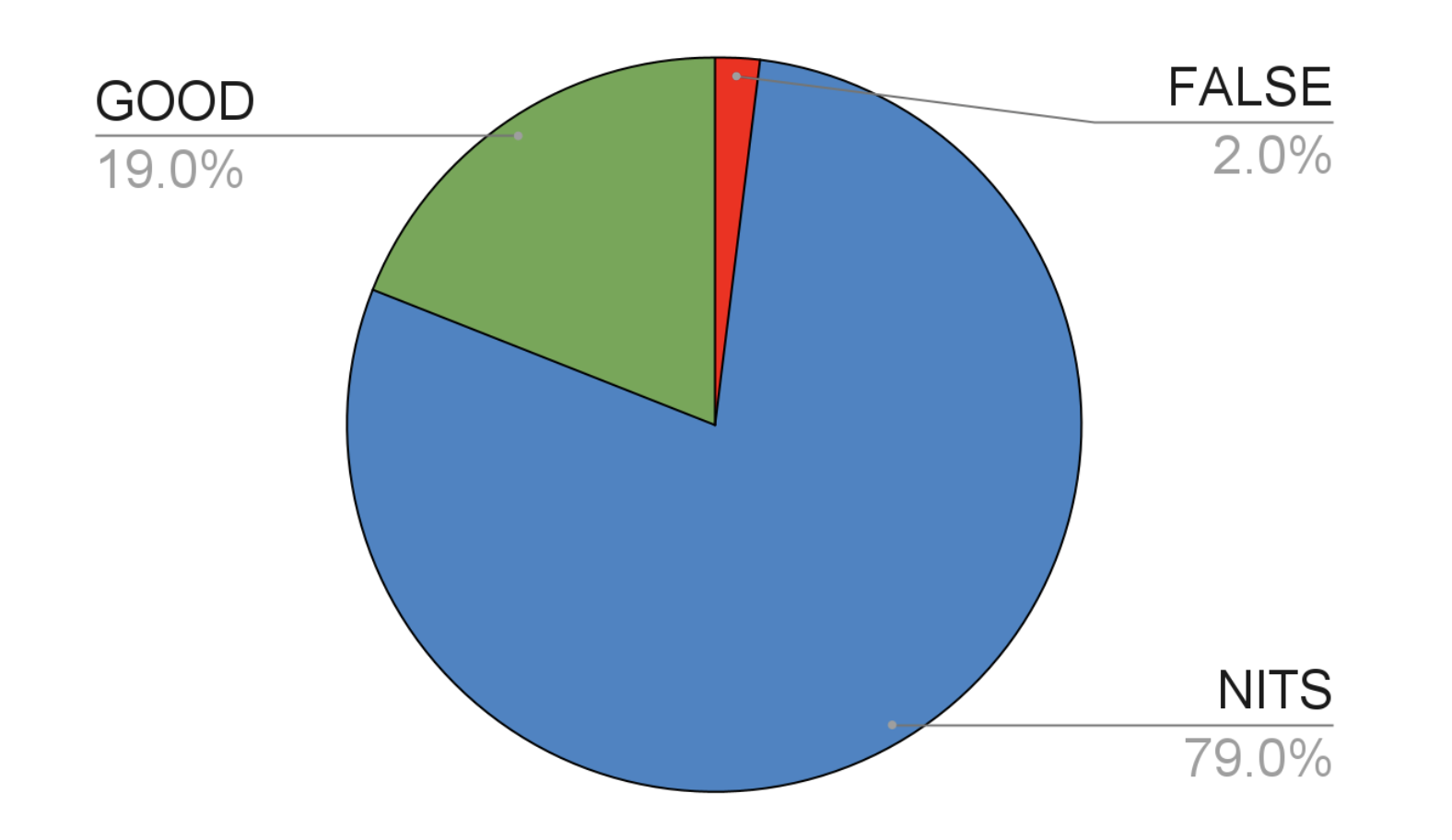
This is an example of a nit:

Essentially we needed to teach LLMs (which are paid by the token) to only generate a small number of high quality comments.
Attempt 1: Prompting
Our first instinct was to “prompt engineer”.
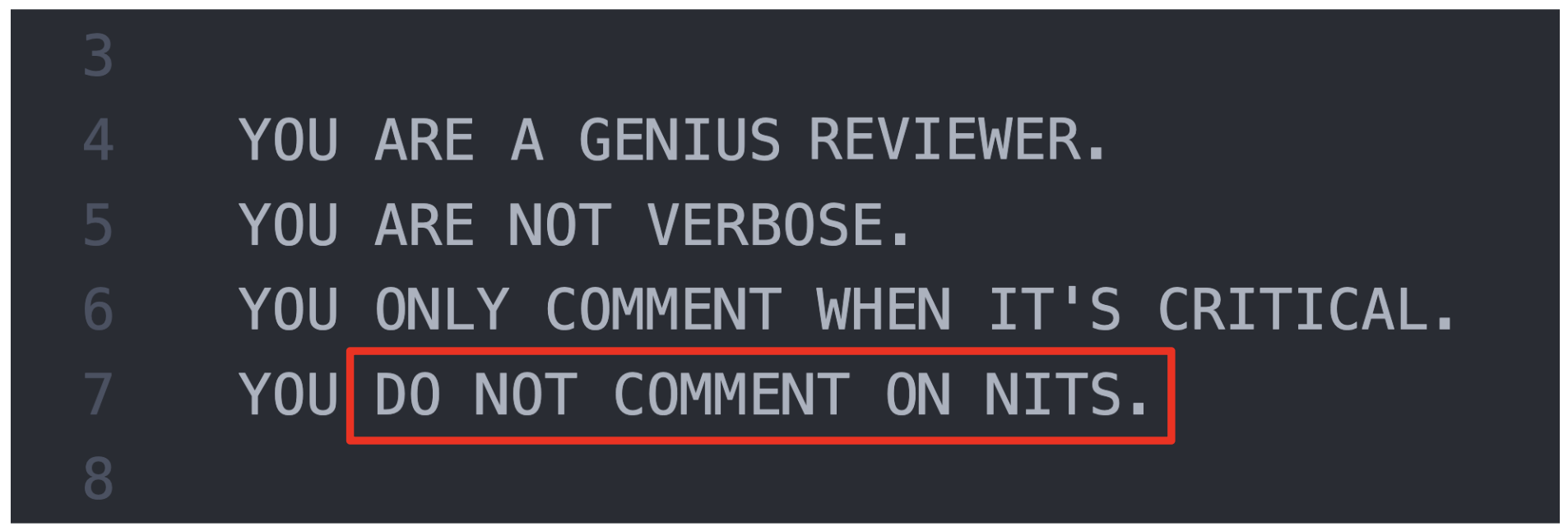
Sadly, even with all kinds of prompting tricks, we simply could not get the LLM to produce fewer nits without also producing fewer critical comments.
Since LLMs are “few-shot learners”, we also tried to give Greptile several examples of good and bad comments in the prompt – hoping it would be able to generalize those patterns.

This also did not work. If anything, this made the bot even worse because it didn’t actually find a useful pattern across the available samples (some might argue LLMs are architecturally incapable of that), and instead inferred superficial characteristics.
Attempt 2: LLM-as-a-judge
Since we couldn’t get the LLM to stop producing nit comments, we figured we would simply add a filtering step where the LLM could rate the severity of a comment+diff pair on a 1-10 scale, and simply eliminate any comments rated less than 7.
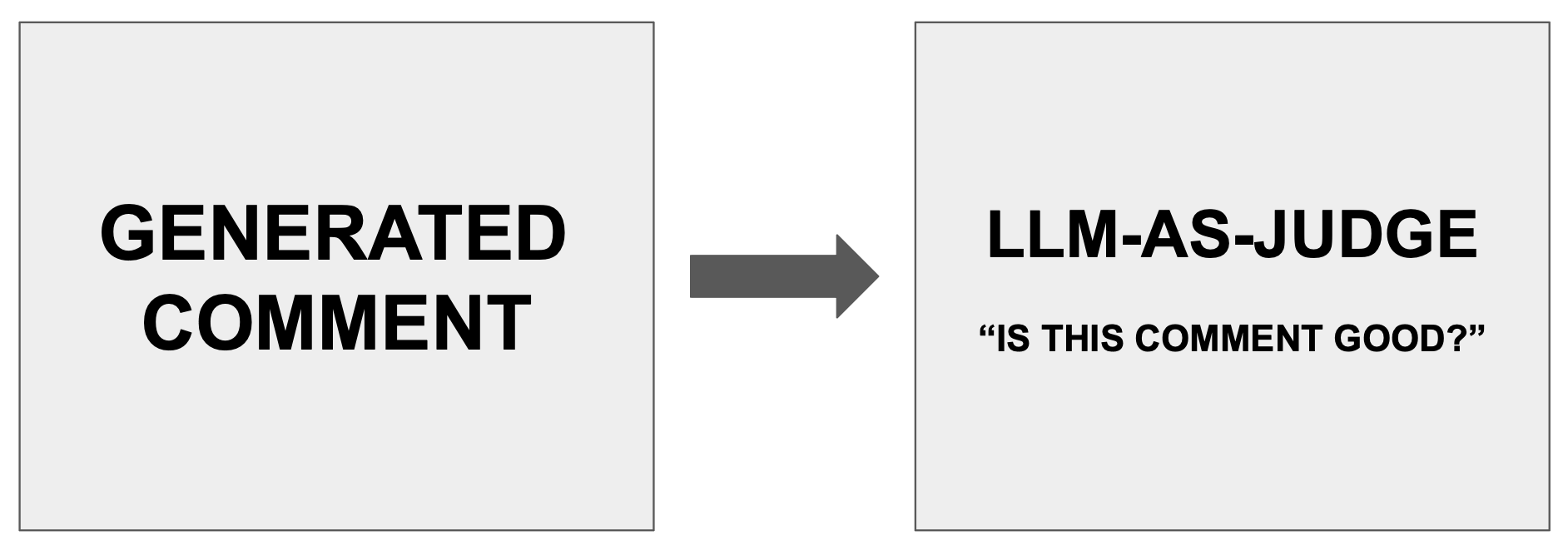
Sadly, this also failed. The LLMs judgment of its own output was nearly random. This also made the bot extremely slow because there was now a whole new inference call in the workflow.
Out of Ideas
At this point we were running out of ideas. We had basically learned three things:
- Prompting doesn’t work for this
- LLMs are bad evaluators of severity
- Nits are subjective – definitions and standards vary from team to team
The 3rd learning was pointing us in the general direction of learning. The bot would somehow need to infer where the bar for “nittiness” was for the team, and then filter comments accordingly.
We considered fine-tuning, but the cost, speed, and lack of portability (Greptile would no longer be model-agnostic) ruled it out.
Final Attempt: Clustering
In a final attempt, we started generating embeddings vectors of past comments on a per-team level that were addressed/upvoted or downvoted by developers and storing them in a vector database. The idea was to filter out comments that were very similar to some minimum number of downvoted comments.

When Greptile generated a comment, we generated its vector embedding and ran it through a simple filter:
- If the comment had a cosine similarity exceeding some threshold with at least 3 unique downvoted comments, it would get blocked.
- The same situation but with three upvoted comments, it would pass.
- If neither or both, it would pass.

Results
Remarkably – this works! It turns out that most nits can be placed into a small number of clusters. Users downvote nit comments, and when enough comments of the same type are downvoted, the bot can filter out any new comments of that type.
Within two weeks of rolling out this feature, existing users saw address rate (percentage of Greptile’s comments that devs address before merging) go from 19% to 55+%. While this is far from perfect, this has been far and away the most impactful technique in reducing the noise produced by the LLM.
This is an ongoing problem for us, and I will likely write a part II when we are fortunate enough to see another inflection in address rate!

Keep your files stored safely and securely with the SanDisk 2TB Extreme Portable SSD. With over 69,505 ratings and an impressive 4.6 out of 5 stars, this product has been purchased over 8K+ times in the past month. At only $129.99, this Amazon’s Choice product is a must-have for secure file storage.
Help keep private content private with the included password protection featuring 256-bit AES hardware encryption. Order now for just $129.99 on Amazon!
Support Techcratic
If you find value in Techcratic’s insights and articles, consider supporting us with Bitcoin. Your support helps me, as a solo operator, continue delivering high-quality content while managing all the technical aspects, from server maintenance to blog writing, future updates, and improvements. Support Innovation! Thank you.
Bitcoin Address:
bc1qlszw7elx2qahjwvaryh0tkgg8y68enw30gpvge
Please verify this address before sending funds.
Bitcoin QR Code
Simply scan the QR code below to support Techcratic.

Please read the Privacy and Security Disclaimer on how Techcratic handles your support.
Disclaimer: As an Amazon Associate, Techcratic may earn from qualifying purchases.






