

























































































2024-12-21 22:12:00
tidyfirst.substack.com
First published 2016.
“I can’t get any code out with all these meetings.” What if this perennial engineer complaint has causation backwards? Adding and removing organizational overhead is relatively easy compared to increasing an organization’s capacity to deploy code. What if meetings and reviews are an organization’s adaptive response to avoid overloading deployment?
Chuck Rossi [ed: legendary release manager at early-to-middle Facebook] made the observation that there seem to be a fixed number of changes Facebook can handle in one deployment. If we want more changes, we need more deployments. This has led to a steady increase in deployment pace over the past five years, from weekly to daily to thrice daily deployments of our PHP code and from six to four to two week cycles for deploying our mobile apps. This improvement has been driven primarily by the release engineering team (I’m a fan, can you tell?)
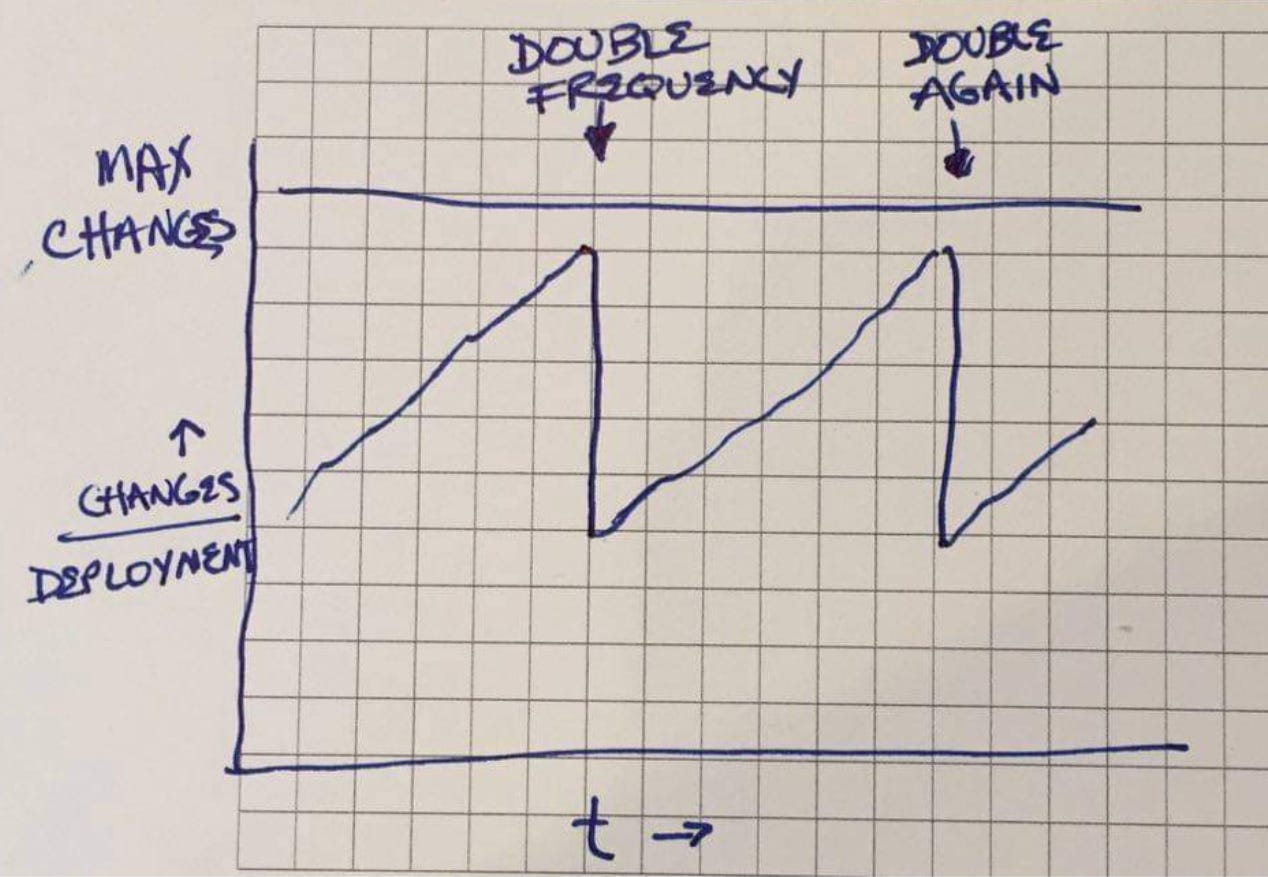
As I was drifting off to sleep yesterday, I visualized the sawtooth-shaped “changes per deployment” graph and it struck me that maybe we had organizational overhead all wrong. “Changes per deployment” seems like an inelastic metric. It’s possible to improve, but only with great effort over time. What happens when the number of changes produced exceeds the current threshold? Changes per deployment doesn’t change. The number of changes has to go down.
How? By increasing overhead—meetings, reviews, handoffs, overhead and eventually by killing enthusiasm and initiative. Nobody is going to own up to doing it on purpose, but perhaps the organization’s emergent response is locally optimal—change the thing that is easiest to change that will relieve the pressure.
Increasing overhead initiates a positive feedback loop: less getting done -> more pressure -> more mistakes -> even fewer changes per deployment -> more overhead -> less getting done. Isolated efforts to reduce overhead increase pressure and increase overhead.
If you want more changes to get through, you need to expand the far end of the hose, to increase deployment capacity. You can do this the hard way, by reducing the deployment cycle and dealing with the ensuing chaos, or the harder way, by increasing the number of changes per deployment (better tests, better monitoring, better isolation between elements, better social relationships on the team). But don’t try to reduce overhead. That’ll just lead inevitably to a series of meetings on how to reduce meetings. At least that will keep you from trying to ship too much code, though.
This essay is an example of the Thinkie Reverse Causality. It’s one of the most fun Thinkies to deploy because they ideas seem just so wrong at first.

Keep your files stored safely and securely with the SanDisk 2TB Extreme Portable SSD. With over 69,505 ratings and an impressive 4.6 out of 5 stars, this product has been purchased over 8K+ times in the past month. At only $129.99, this Amazon’s Choice product is a must-have for secure file storage.
Help keep private content private with the included password protection featuring 256-bit AES hardware encryption. Order now for just $129.99 on Amazon!
Support Techcratic
If you find value in Techcratic’s insights and articles, consider supporting us with Bitcoin. Your support helps me, as a solo operator, continue delivering high-quality content while managing all the technical aspects, from server maintenance to blog writing, future updates, and improvements. Support Innovation! Thank you.
Bitcoin Address:
bc1qlszw7elx2qahjwvaryh0tkgg8y68enw30gpvge
Please verify this address before sending funds.
Bitcoin QR Code
Simply scan the QR code below to support Techcratic.

Please read the Privacy and Security Disclaimer on how Techcratic handles your support.
Disclaimer: As an Amazon Associate, Techcratic may earn from qualifying purchases.






