












































































![for Tesla Model 3 2025 Dashboard Cover,[Anti-Glare and Dustproof] Suede Dashboard Pad…](https://techcratic.com/wp-content/uploads/2025/08/61yHoBc6VfL._AC_SL1500_-360x180.jpg)












Jesse Clayton
2025-05-08 09:00:00
blogs.nvidia.com
As AI use cases continue to expand — from document summarization to custom software agents — developers and enthusiasts are seeking faster, more flexible ways to run large language models (LLMs).
Running models locally on PCs with NVIDIA GeForce RTX GPUs enables high-performance inference, enhanced data privacy and full control over AI deployment and integration. Tools like LM Studio — free to try — make this possible, giving users an easy way to explore and build with LLMs on their own hardware.
LM Studio has become one of the most widely adopted tools for local LLM inference. Built on the high-performance llama.cpp runtime, the app allows models to run entirely offline and can also serve as OpenAI-compatible application programming interface (API) endpoints for integration into custom workflows.
The release of LM Studio 0.3.15 brings improved performance for RTX GPUs thanks to CUDA 12.8, significantly improving model load and response times. The update also introduces new developer-focused features, including enhanced tool use via the “tool_choice” parameter and a redesigned system prompt editor.
The latest improvements to LM Studio improve its performance and usability — delivering the highest throughput yet on RTX AI PCs. This means faster responses, snappier interactions and better tools for building and integrating AI locally.
Where Everyday Apps Meet AI Acceleration
LM Studio is built for flexibility — suited for both casual experimentation or full integration into custom workflows. Users can interact with models through a desktop chat interface or enable developer mode to serve OpenAI-compatible API endpoints. This makes it easy to connect local LLMs to workflows in apps like VS Code or bespoke desktop agents.
For example, LM Studio can be integrated with Obsidian, a popular markdown-based knowledge management app. Using community-developed plug-ins like Text Generator and Smart Connections, users can generate content, summarize research and query their own notes — all powered by local LLMs running through LM Studio. These plug-ins connect directly to LM Studio’s local server, enabling fast, private AI interactions without relying on the cloud.
The 0.3.15 update adds new developer capabilities, including more granular control over tool use via the “tool_choice” parameter and an upgraded system prompt editor for handling longer or more complex prompts.
The tool_choice parameter lets developers control how models engage with external tools — whether by forcing a tool call, disabling it entirely or allowing the model to decide dynamically. This added flexibility is especially valuable for building structured interactions, retrieval-augmented generation (RAG) workflows or agent pipelines. Together, these updates enhance both experimentation and production use cases for developers building with LLMs.
LM Studio supports a broad range of open models — including Gemma, Llama 3, Mistral and Orca — and a variety of quantization formats, from 4-bit to full precision.
Common use cases span RAG, multi-turn chat with long context windows, document-based Q&A and local agent pipelines. And by using local inference servers powered by the NVIDIA RTX-accelerated llama.cpp software library, users on RTX AI PCs can integrate local LLMs with ease.
Whether optimizing for efficiency on a compact RTX-powered system or maximizing throughput on a high-performance desktop, LM Studio delivers full control, speed and privacy — all on RTX.
Experience Maximum Throughput on RTX GPUs
At the core of LM Studio’s acceleration is llama.cpp — an open-source runtime designed for efficient inference on consumer hardware. NVIDIA partnered with the LM Studio and llama.cpp communities to integrate several enhancements to maximize RTX GPU performance.
Key optimizations include:
- CUDA graph enablement: Groups multiple GPU operations into a single CPU call, reducing CPU overhead and improving model throughput by up to 35%.
- Flash attention CUDA kernels: Boosts throughput by up to 15% by improving how LLMs process attention — a critical operation in transformer models. This optimization enables longer context windows without increasing memory or compute requirements.
- Support for the latest RTX architectures: LM Studio’s update to CUDA 12.8 ensures compatibility with the full range of RTX AI PCs — from GeForce RTX 20 Series to NVIDIA Blackwell-class GPUs, giving users the flexibility to scale their local AI workflows from laptops to high-end desktops.
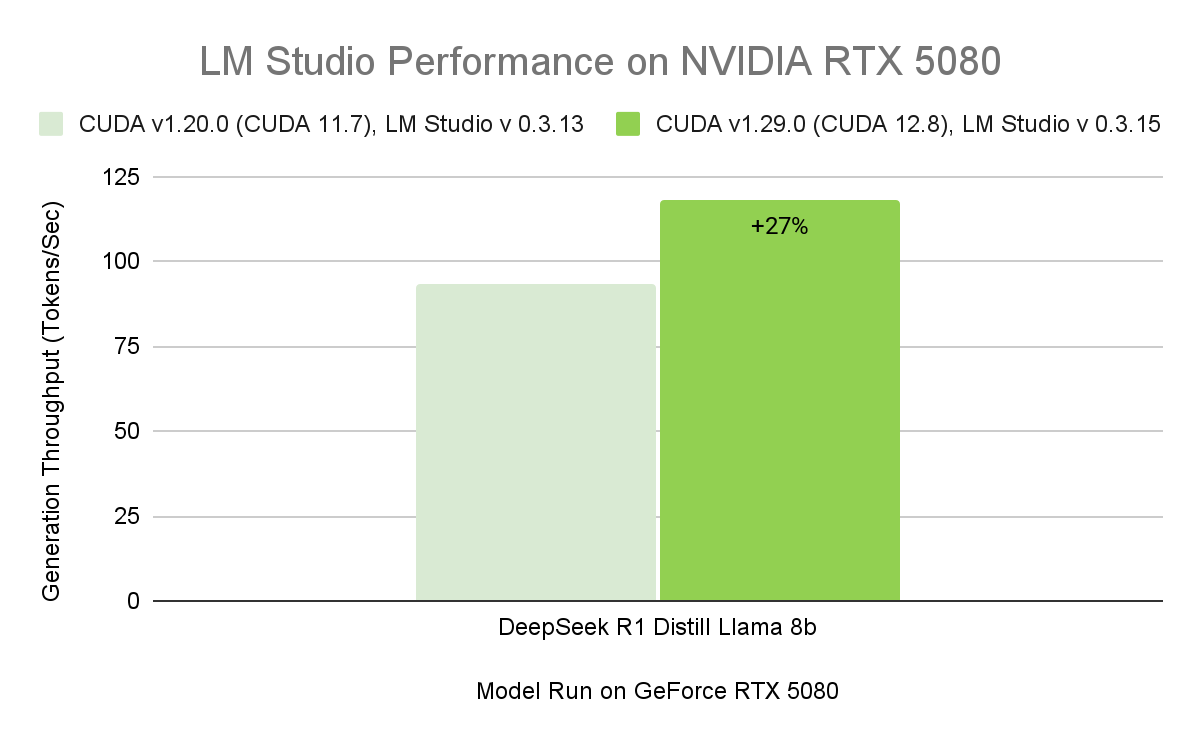
With a compatible driver, LM Studio automatically upgrades to the CUDA 12.8 runtime, enabling significantly faster model load times and higher overall performance.
These enhancements deliver smoother inference and faster response times across the full range of RTX AI PCs — from thin, light laptops to high-performance desktops and workstations.
Get Started With LM Studio
LM Studio is free to download and runs on Windows, macOS and Linux. With the latest 0.3.15 release and ongoing optimizations, users can expect continued improvements in performance, customization and usability — making local AI faster, more flexible and more accessible.
Users can load a model through the desktop chat interface or enable developer mode to expose an OpenAI-compatible API.
To quickly get started, download the latest version of LM Studio and open up the application.
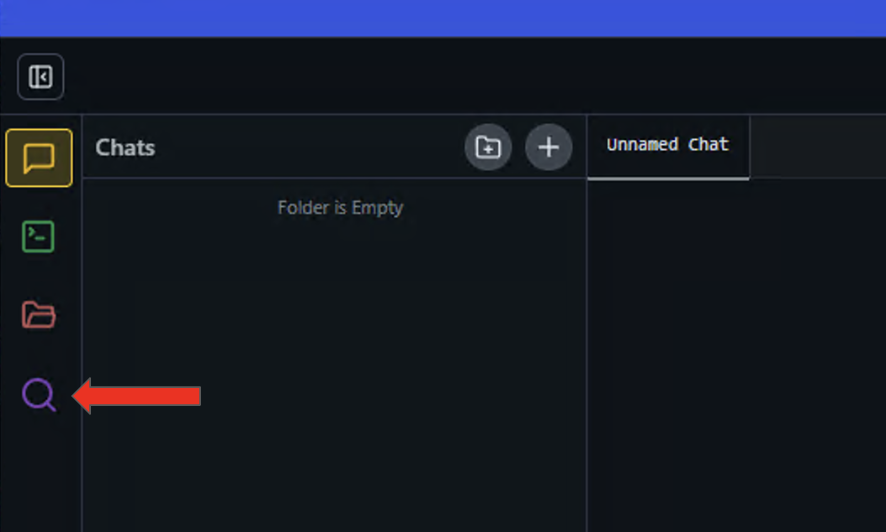
- Click the magnifying glass icon on the left panel to open up the Discover menu.
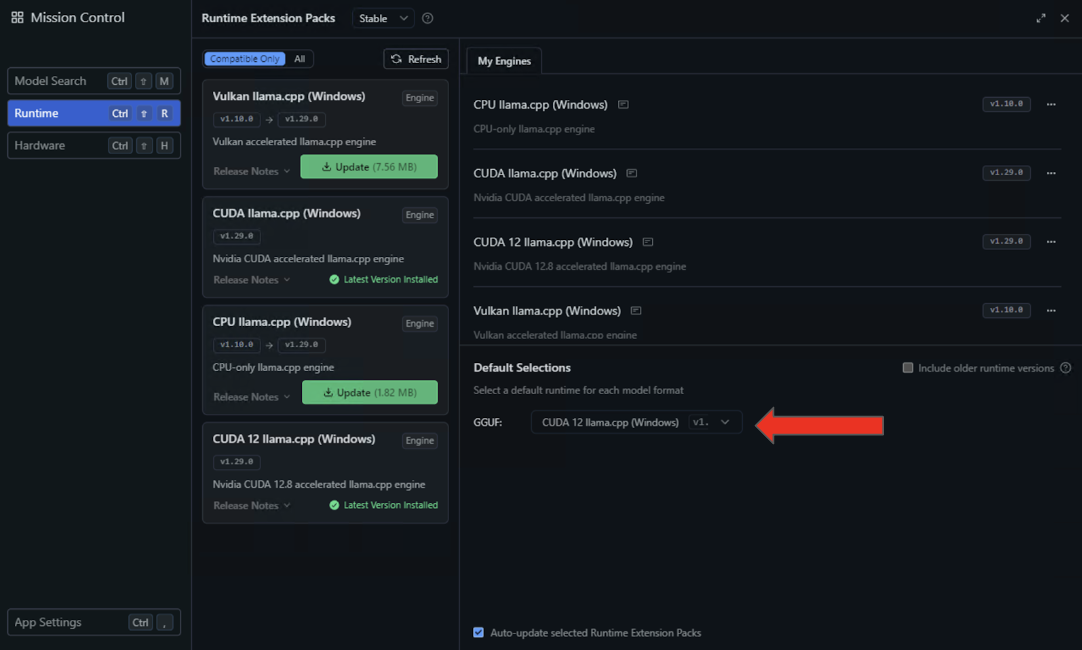
- Select the Runtime settings on the left panel and search for the CUDA 12 llama.cpp (Windows) runtime in the availability list. Select the button to Download and Install.
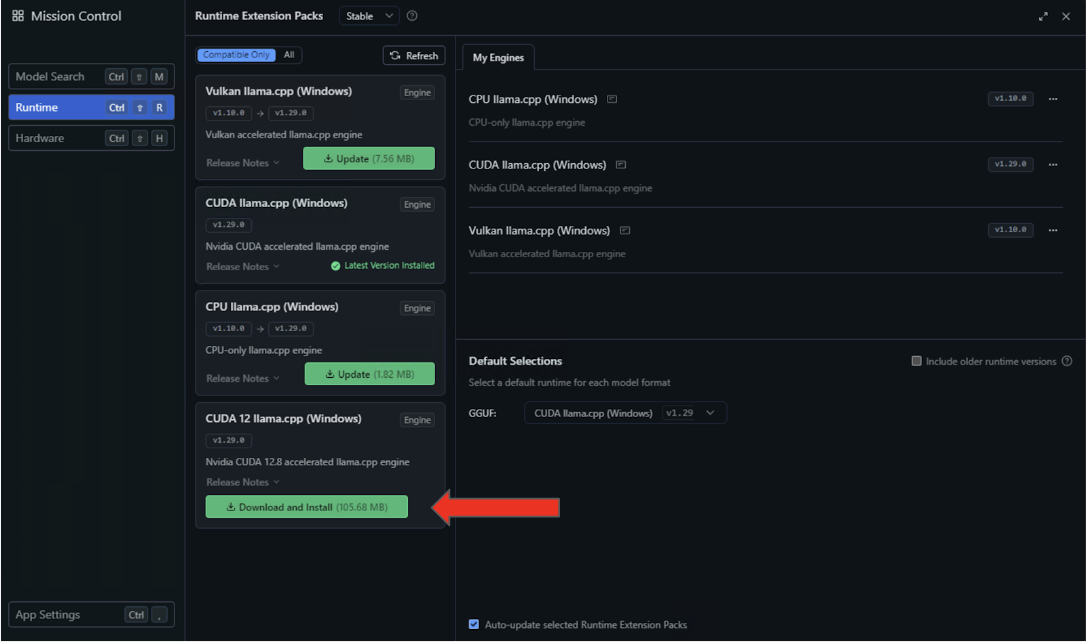
- After the installation completes, configure LM Studio to use this runtime by default by selecting CUDA 12 llama.cpp (Windows) in the Default Selections dropdown.
- For the final steps in optimizing CUDA execution, load a model in LM Studio and enter the Settings menu by clicking the gear icon to the left of the loaded model.

- From the resulting dropdown menu, toggle “Flash Attention” to be on and offload all model layers onto the GPU by dragging the “GPU Offload” slider to the right.
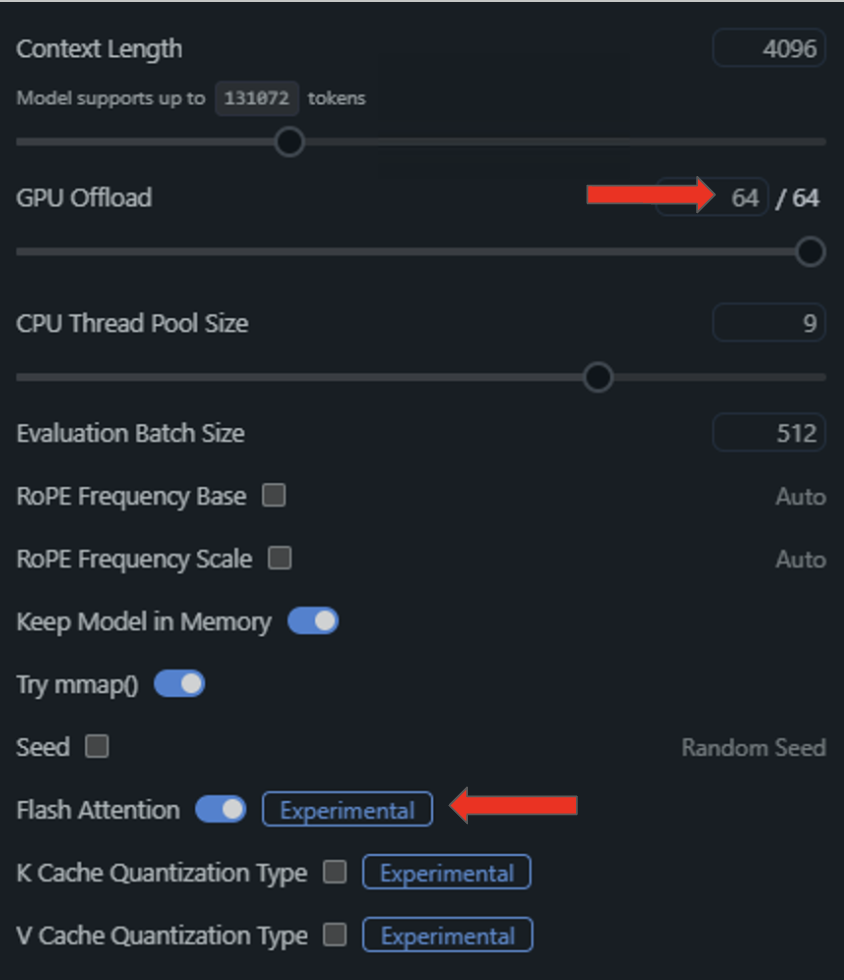
Once these features are enabled and configured, running NVIDIA GPU inference on a local setup is good to go.
LM Studio supports model presets, a range of quantization formats and developer controls like tool_choice for fine-tuned inference. For those looking to contribute, the llama.cpp GitHub repository is actively maintained and continues to evolve with community- and NVIDIA-driven performance enhancements.
Each week, the RTX AI Garage blog series features community-driven AI innovations and content for those looking to learn more about NVIDIA NIM microservices and AI Blueprints, as well as building AI agents, creative workflows, digital humans, productivity apps and more on AI PCs and workstations.
Plug in to NVIDIA AI PC on Facebook, Instagram, TikTok and X — and stay informed by subscribing to the RTX AI PC newsletter.

Take your gaming to the next level! The Redragon S101 RGB Backlit Gaming Keyboard is an Amazon’s Choice product that delivers incredible value. This all-in-one PC Gamer Value Kit includes a Programmable Backlit Gaming Mouse, perfect for competitive gaming or casual use.
With 46,015 ratings, an average of 4.6 out of 5 stars, and over 4K+ bought in the past month, this kit is trusted by gamers everywhere! Available now for just $39.99 on Amazon. Plus, act fast and snag an exclusive 15% off coupon – but hurry, this offer won’t last long!
Help Power Techcratic’s Future – Scan To Support
If Techcratic’s content and insights have helped you, consider giving back by supporting the platform with crypto. Every contribution makes a difference, whether it’s for high-quality content, server maintenance, or future updates. Techcratic is constantly evolving, and your support helps drive that progress.
As a solo operator who wears all the hats, creating content, managing the tech, and running the site, your support allows me to stay focused on delivering valuable resources. Your support keeps everything running smoothly and enables me to continue creating the content you love. I’m deeply grateful for your support, it truly means the world to me! Thank you!
|
BITCOIN
bc1qlszw7elx2qahjwvaryh0tkgg8y68enw30gpvge Scan the QR code with your crypto wallet app |
|
DOGECOIN
D64GwvvYQxFXYyan3oQCrmWfidf6T3JpBA Scan the QR code with your crypto wallet app |
|
ETHEREUM
0xe9BC980DF3d985730dA827996B43E4A62CCBAA7a Scan the QR code with your crypto wallet app |






Please read the Privacy and Security Disclaimer on how Techcratic handles your support.
Disclaimer: As an Amazon Associate, Techcratic may earn from qualifying purchases.








