

























































































The Robot Report Staff
2025-07-14 11:45:00
www.therobotreport.com
Liquid AI said that with its foundation models, it hopes to achieve the optimal balance between quality, latency, and memory for specific tasks and hardware requirements. | Source: Liquid AI
This week, Liquid AI released LFM2, a Liquid Foundation Model (LFM) that the company said sets a new standard in quality, speed, and memory efficiency deployment.
Shifting large generative models from distant clouds to lean, on‑device LLMs unlocks millisecond latency, offline resilience, and data‑sovereign privacy. These are capabilities essential for phones, laptops, cars, robots, wearables, satellites, and other endpoints that must reason in real time.
Liquid AI designed the model to provide a fast on-device gen-AI experience across the industry, unlocking a massive number of devices for generative AI workloads. Built on a new hybrid architecture, LFM2 delivers twice as fast decode and prefill performance as Qwen3 on CPU. It also significantly outperforms models in each size class, making them ideal for powering efficient AI agents, the company said.
The Cambridge, Mass.-based company said these performance gains make LFM2 the ideal choice for local and edge use cases. Beyond deployment benefits, its new architecture and training infrastructure deliver a three times improvement in training efficiency over the previous LFM generation.
Liquid AI co-founder and director of MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) Daniela Rus delivered a keynote at the Robotics Summit & Expo 2025, a robotics development event produced by The Robot Report.
LFM2 models are available today on Hugging Face. Liquid AI is releasing them under an open license, which is based on Apache 2.0. The license allows users to freely use LFM2 models for academic and research purposes. Companies can also use the models commercially if they’re smaller (under $10m revenue).
Liquid AI offers small multimodal foundation models with a secure enterprise-grade deployment stack that turns every device into an AI device, locally. This, it said, gives it the opportunity to obtain an outsized share on the market as enterprises pivot from cloud LLMs to cost-efficient, fast, private, and on‑prem intelligence.
What can LFM2 do?
Liquid AI said LFM2 achieves three times faster training compared to its previous generation. It also benefits from up to two times faster decode and prefill speed on CPU compared to Qwen3. Additionally, the company claimed LFM2 outperforms similarly-sized models across multiple benchmark categories, including knowledge, mathematics, instruction following, and multilingual capabilities.
LFM2 is equipped with a new architecture. It is a hybrid Liquid model with multiplicative gates and short convolutions. It consists of 16 blocks: 10 double-gated short-range convolution blocks and 6 blocks of grouped query attention.
Whether it is deployed on smartphones, laptops, or vehicles, LFM2 runs efficiently on CPU, GPU, and NPU hardware. The company’s full-stack system includes architecture, optimization, and deployment engines to accelerate the path from prototype to product.
Liquid AI is releasing the weights of three dense checkpoints with 0.35B, 0.7B, and 1.2B parameters. Users can try them now on the Liquid Playground, Hugging Face, and OpenRouter.
How does LFM2 perform against other models?
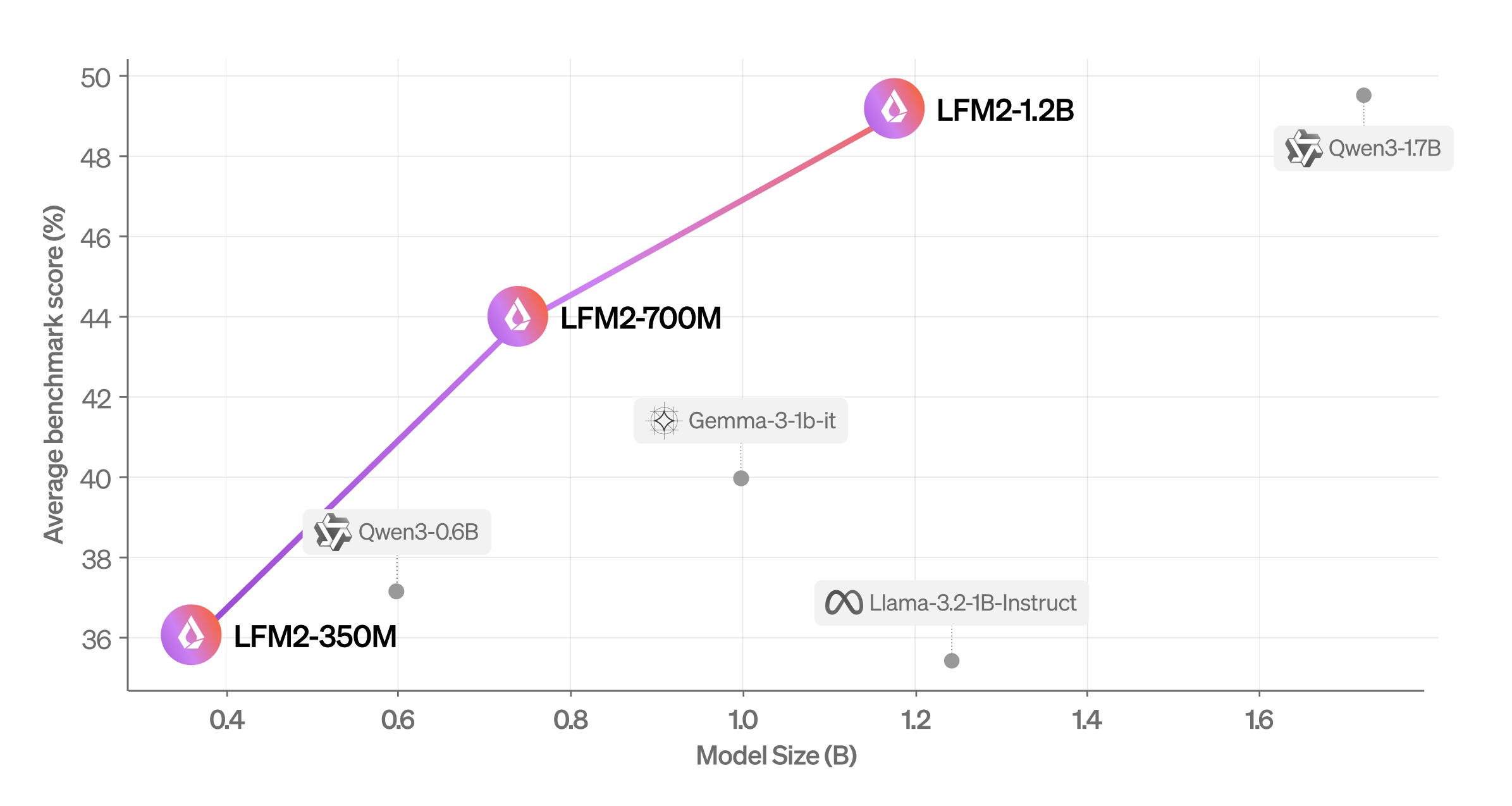
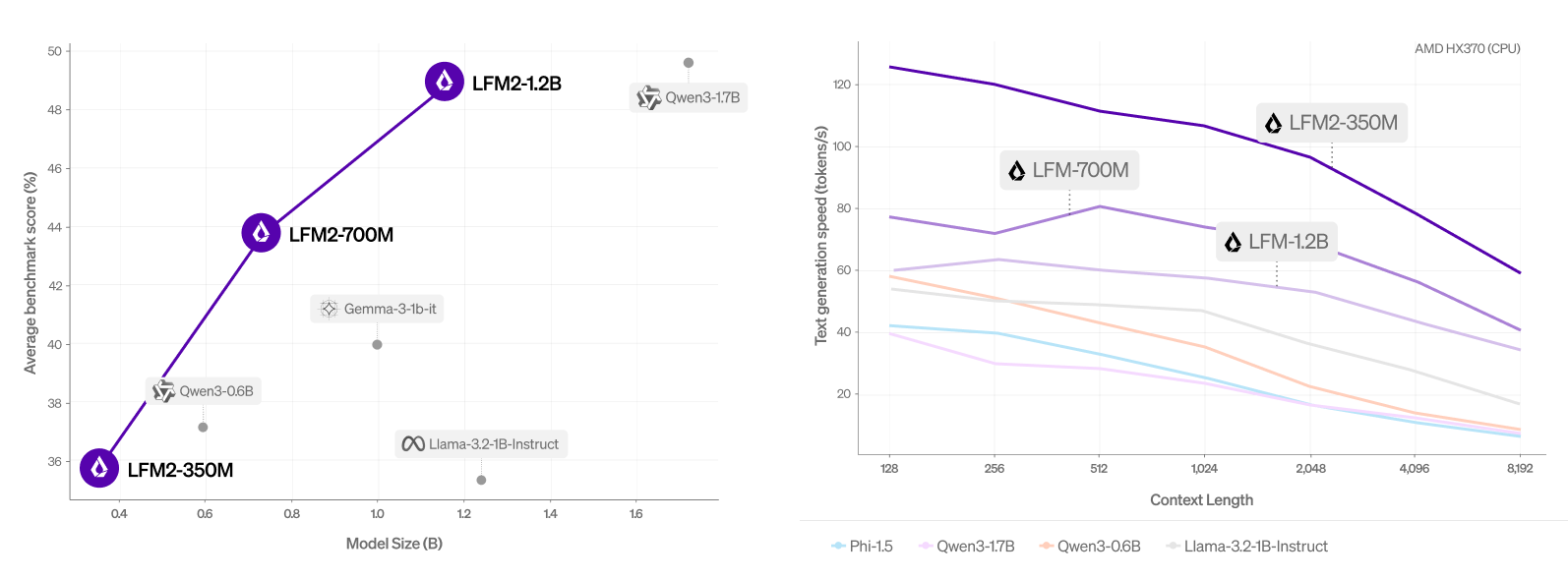
Average score (MMLU, IFEval, IFBENCH, GSM8K, MMMLU) vs. model size. | Source: Liquid AI
The company evaluated LFM2 using automated benchmarks and an LLM-as-a-Judge framework to obtain a comprehensive overview of its capabilities. It found that the model outperforms similar-sized models across different evaluation categories.
Liquid AI also evaluated LFM2 across seven popular benchmarks covering knowledge (5-shot MMLU, 0-shot GPQA), instruction following (IFEval, IFBench), mathematics (0-shot GSM8K, 5-shot MGSM), and multilingualism (5-shot OpenAI MMMLU, 5-shot MGSM again) with seven languages (Arabic, French, German, Spanish, Japanese, Korean, and Chinese).
It found that LFM2-1.2B performs competitively with Qwen3-1.7B, a model with a 47% bigger parameter count. LFM2-700M outperforms Gemma 3 1B IT, and its tiniest checkpoint, LFM2-350M, is competitive with Qwen3-0.6B and Llama 3.2 1B Instruct.
How Liquid AI trained LFM2
To train and scale-up LFM2, the company selected three model sizes (350M, 700M, and 1.2B parameters) targeting low-latency on-device language model workloads. All models were trained on 10T tokens drawn from a pre-training corpus comprising approximately 75% English, 20% multilingual, and 5% code data sourced from the web and licensed materials.
For the multilingual capabilities of LFM2 the company primarily focused on Japanese, Arabic, Korean, Spanish, French, and German languages.
During pre-training, Liquid AI leveraged its existing LFM1-7B as a teacher model in a knowledge distillation framework. The company used the cross-entropy between LFM2’s student outputs and the LFM1-7B teacher outputs as the primary training signal throughout the entire 10T token training process. The context length was extended during pretraining to 32k.
Post-training started with a very large-scale Supervised Fine-Tuning (SFT) stage on a diverse data mixture to unlock generalist capabilities. For these small models, the company found it beneficial to directly train on a representative set of downstream tasks, such as RAG or function calling. The dataset is comprised of open-source, licensed, as well as targeted synthetic data, where the company ensures high quality through a combination of quantitative sample scoring and qualitative heuristics.
Liquid AI further applies a custom Direct Preference Optimization algorithm with length normalization on a combination of offline data and semi-online data. The semi-online dataset is generated by sampling multiple completions from its model, based on a seed SFT dataset.
The company then scores all responses with LLM judges and creates preference pairs by combining the highest and lowest scored completions among the SFT and on-policy samples. Both the offline and semi-online datasets are further filtered based on a score threshold. Liquid AI creates multiple candidate checkpoints by varying the hyperparameters and dataset mixtures. Finally, it combines a selection of its best checkpoints into a final model via different model merging techniques.

Keep track of your essentials with the Apple AirTag 4 Pack, the ultimate tracking solution for your belongings. With over 5,972 ratings and a stellar 4.7-star average, this product has quickly become a customer favorite. Over 10,000 units were purchased in the past month, solidifying its status as a highly rated Amazon Choice product.
For just $79.98, you can enjoy peace of mind knowing your items are always within reach. Order now for only $79.98 at Amazon!
Help Power Techcratic’s Future – Scan To Support
If Techcratic’s content and insights have helped you, consider giving back by supporting the platform with crypto. Every contribution makes a difference, whether it’s for high-quality content, server maintenance, or future updates. Techcratic is constantly evolving, and your support helps drive that progress.
As a solo operator who wears all the hats, creating content, managing the tech, and running the site, your support allows me to stay focused on delivering valuable resources. Your support keeps everything running smoothly and enables me to continue creating the content you love. I’m deeply grateful for your support, it truly means the world to me! Thank you!
|
BITCOIN
bc1qlszw7elx2qahjwvaryh0tkgg8y68enw30gpvge Scan the QR code with your crypto wallet app |
|
DOGECOIN
D64GwvvYQxFXYyan3oQCrmWfidf6T3JpBA Scan the QR code with your crypto wallet app |
|
ETHEREUM
0xe9BC980DF3d985730dA827996B43E4A62CCBAA7a Scan the QR code with your crypto wallet app |






Please read the Privacy and Security Disclaimer on how Techcratic handles your support.
Disclaimer: As an Amazon Associate, Techcratic may earn from qualifying purchases.








