


































![Majora's Mask Walkthrough – Bad Time Management [Part 39]](https://techcratic.com/wp-content/uploads/2025/09/1757202435_maxresdefault-360x180.jpg)






















![Nintendo DSi – Matte Black (Renewed) [video game]](https://techcratic.com/wp-content/uploads/2025/09/41I5o383cVL-360x180.jpg)































2025-08-08 08:57:00
radar.com
At Radar, performance is a feature. Our platform processes over 1 billion API calls per day from hundreds of millions of devices worldwide. We provide geolocation infrastructure and solutions, including APIs for:
- Geocoding: Forward geocoding, reverse geocoding, and IP geocoding APIs with global coverage.
- Search: Address autocomplete, address validation, and places search APIs.
- Routing: Distance, matrix, route optimization, route matching, and directions APIs.
- Geolocation compliance: Detect current jurisdiction, distance to border, regulatory exclusion zones, and more.
But as our products and data scale, so do our engineering challenges.
To support this growth, we developed HorizonDB, a geospatial database written in Rust that consolidates multiple location services into a single, highly performant binary. With HorizonDB, we are able to power all of the above use cases with excellent operational footprint:
- Handle 1,000 QPS per core.
- Maintain a forward geocoding median latency of 50 ms.
- Maintain a reverse geocoding median latency of
- Scale linearly on commodity hardware.
Why we replaced Mongo and Elasticsearch
Before HorizonDB, we split geocoding across Elasticsearch and microservices for forward geocoding, and MongoDB for reverse.
Operating and scaling this stack was costly: Elasticsearch frequently fanned queries to all shards and required service-orchestrated batch updates, while MongoDB lacked true batch ingestion, required overprovisioning, and had no reliable bulk rollback for bad data.
The architecture
Our goals for this service included:
- Efficiency: The service can run on commodity machines, has predictable autoscaling, and is the single source of truth of all our geo entities.
- Operations: Data assets can be built and processed multiple times a day, changes can be deployed and rolled back trivially, and should be simple to operate.
- Developer experience: Developers should be able to run the service locally, and changes can be written and tested easily.
With these goals in mind, we built HorizonDB using RocksDB, S2, Tantivy, FSTs, LightGBM and FastText.
Data assets are preprocessed using Apache Spark, ingested in Rust and stored as versioned assets in AWS S3.
.png)
Rust
https://www.rust-lang.org/
A compiled language designed by Mozilla meant for systems programming. There are many aspects the team liked about Rust:
- Compiled and memory safety without garbage collection: Rust’s strong type system and safe and expressive concurrency in the form of Rayon and Tokio lets us write performant code without sacrificing readability. Rust makes it trivial to manage memory without garbage collection, allowing us to manage large indexes of data in memory with predictable latency.
- Higher-order abstractions: Many of our engineers work with higher-level languages where expressive list operations, null-handling, and pattern matching are a given. Rust has these primitives, so that our team can move fast and express logic cleanly, which is important when dealing with complex logic such as search ranking.
- Multi-threaded not multi-process: Since HorizonDB needs to fetch hundreds of GB of data from SSDs, having a single process that can leverage the same memory address space is more efficient compared to our API layer language TypeScript deployed to Node.js, which dedicates a new process to every core.
RocksDB
https://rocksdb.org/
An in-process Log-Structured Merge (LSM) tree, serves as our primary record store. It’s incredibly fast, typically achieving microsecond response times (even with a much larger dataset, faster than other high performance solutions).
S2
http://s2geometry.io/
S2 is Google’s spatial indexing library that projects a quadtree onto a sphere, turning O(n) point-in-polygon lookups into cacheable constant time lookups. While writing HorizonDB we wrote Rust bindings for Google’s C++ library that we will open source soon.
FSTs
https://github.com/BurntSushi/fst
FSTs are a data structure offering efficient string compression and prefix queries. This blog post by Andrew Gallant describes in great detail how this is achieved. We found 80% of our queries were well-formed and wanted an efficient way to cache these “happy-paths”. Using FSTs, we were able to cache millions of these happy-paths on the order of MBs of memory and often returned prefix candidates within single-digit milliseconds.
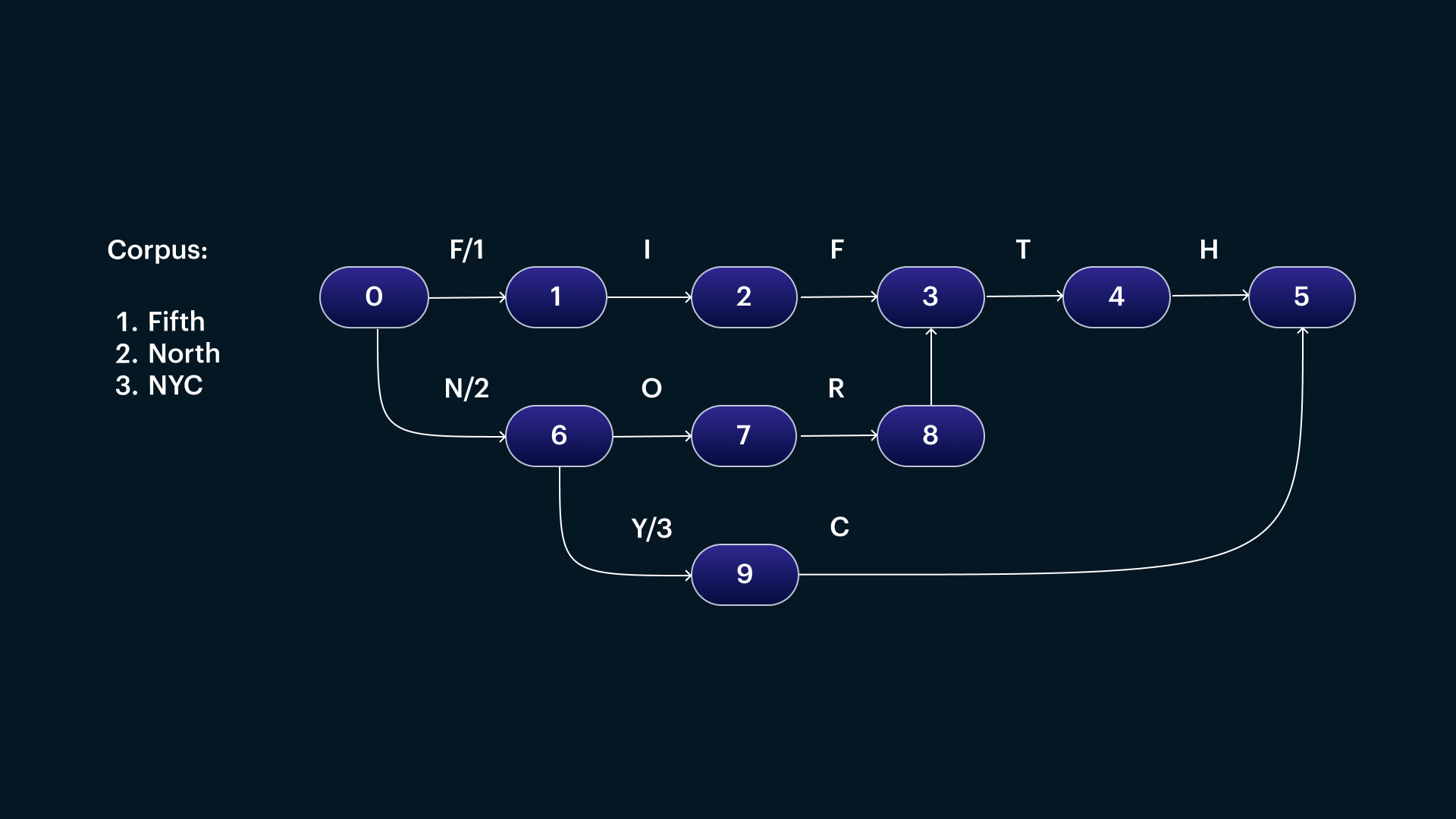
Tantivy
https://github.com/quickwit-oss/tantivy
An in-process inverted index library similar to Lucene.
We made the decision to use an in-process index over an external service such as Elasticsearch or Meilisearch for a few reasons:
- Search quality: To improve our recall for use cases like address validation, we often “expand” our search keywords dynamically. This would translate to sending multiple queries over the wire if we used an external service.
- Operational simplicity: Everything is within the same process, so scaling search servers becomes trivial. Memory mapping gives us a way to efficiently use commodity hardware with large indexes. We found this much simpler than scaling Elasticsearch where tuning JVM params and trying to saturate CPU without increased latency was very difficult.
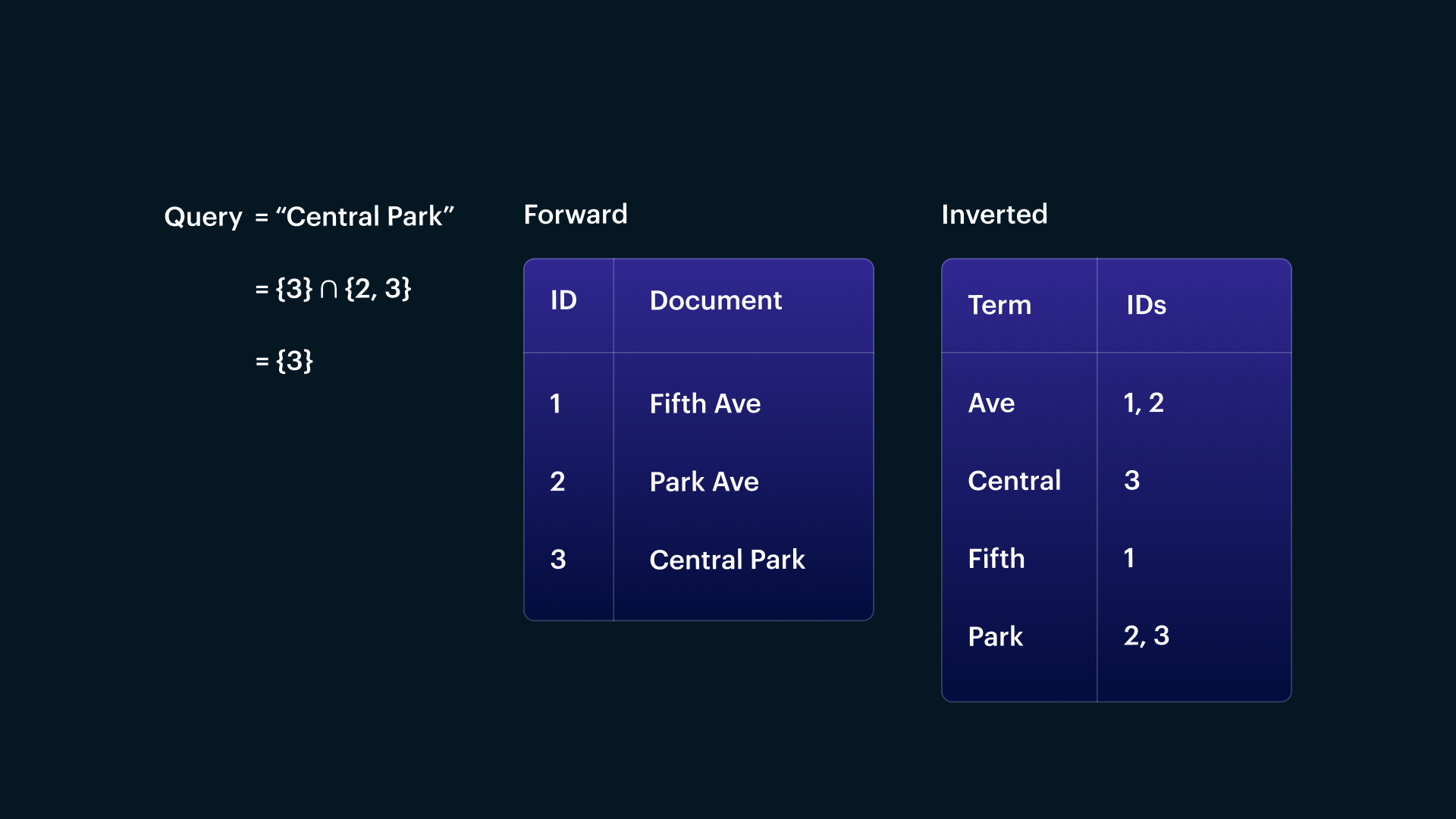
FastText
https://fasttext.cc/
To improve precision and search quality, we implemented a FastText model trained from a mix of our geocoder corpus and query logs. With FastText, we can semantically represent words in a query in a numeric vector format, suitable for ML applications. FastText is typo-tolerant and handles out-of-vocabulary words with its use of ngrams. “Nearby” vectors represent semantically similar words allowing our ML algorithms to understand semantics of a given word in a search query.
LightGBM
https://github.com/microsoft/LightGBM
We have trained multiple LightGBM models to classify query intent and tag parts of our query depending on the intent. This allows us to “structure” our queries, improving search performance and precision. For example, a query deemed as a regional query such as “New York” can skip address search, whereas a query like “841 broadway” allows us to skip searching POIs and regions.
Apache Spark
https://spark.apache.org/
With Spark, we are able to process hundreds of millions of data points in less than an hour, with near-linear scalability. We often had to tune or refactor jobs to achieve optimal performance when performing joins or aggregations.
Since our data is written to S3, it becomes trivial to inspect results via Amazon Athena, a hosted deployment of Apache Presto that can read object storage assets using SQL. DuckDB is another lightweight tool that our engineers use to inspect these assets on the fly.
Results
HorizonDB has transformed both the operational and developmental aspects of our geolocation offerings. We’ve achieved improvements across the board for cost, performance, and scalability:
- Our service is now faster, operationally simple, and reliable.
- Our developers are able to move fast with new features and data changes. We are able to ingest and evaluate new data sources within a day.
- We’ve shut down multiple Mongo clusters, a large Elasticsearch cluster, and several geo microservices, saving us high five-figures in monthly costs.
We are happy with our design decisions with HorizonDB and are prepared for our scale for the foreseeable future. We will touch on how we designed particular features of the system in future blog posts.
Many thanks to our hard-working engineers Bradley Schoeneweis, Jason Liu, Jacky Wang, Binh Robles, Greg Sadetsky, David Gurevich, and Felix Li who made this system a reality.
Join us
Radar is more than just an API layer. Across SDKs, maps, databases, and infrastructure, we’re rethinking geolocation from the ground up to offer the fastest, most developer-friendly location stack available.
If this blog post was interesting to you, we’re hiring great engineering talent across the board.
Check out our jobs page for more information.

Keep your files stored safely and securely with the SanDisk 2TB Extreme Portable SSD. With over 69,505 ratings and an impressive 4.6 out of 5 stars, this product has been purchased over 8K+ times in the past month. At only $129.99, this Amazon’s Choice product is a must-have for secure file storage.
Help keep private content private with the included password protection featuring 256-bit AES hardware encryption. Order now for just $129.99 on Amazon!
Help Power Techcratic’s Future – Scan To Support
If Techcratic’s content and insights have helped you, consider giving back by supporting the platform with crypto. Every contribution makes a difference, whether it’s for high-quality content, server maintenance, or future updates. Techcratic is constantly evolving, and your support helps drive that progress.
As a solo operator who wears all the hats, creating content, managing the tech, and running the site, your support allows me to stay focused on delivering valuable resources. Your support keeps everything running smoothly and enables me to continue creating the content you love. I’m deeply grateful for your support, it truly means the world to me! Thank you!
|
BITCOIN
bc1qlszw7elx2qahjwvaryh0tkgg8y68enw30gpvge Scan the QR code with your crypto wallet app |
|
DOGECOIN
D64GwvvYQxFXYyan3oQCrmWfidf6T3JpBA Scan the QR code with your crypto wallet app |
|
ETHEREUM
0xe9BC980DF3d985730dA827996B43E4A62CCBAA7a Scan the QR code with your crypto wallet app |






Please read the Privacy and Security Disclaimer on how Techcratic handles your support.
Disclaimer: As an Amazon Associate, Techcratic may earn from qualifying purchases.







