
































![Gamer [Blu-ray]](https://techcratic.com/wp-content/uploads/2025/07/71bzLLBjNyS._SL1500_-360x180.jpg)



































2024-12-13 14:47:00
blog.terrafloww.com
The rapid growth of Earth observation data in cloud storage, which will continue to grow exponentially, powered by falling rocket launch prices by companies like SpaceX, has pushed us to think of how we access and analyze satellite imagery. With major space agencies like ESA and NASA adopting Cloud-Optimized GeoTIFFs (COGs) as their standard format, we’re seeing unprecedented volumes of data becoming available through public cloud buckets.
This accessibility brings new challenges around efficient data access. In this article, we introduce an alternative approach to cloud-based raster data access, building upon the foundational work of GDAL and Rasterio.
The Evolution of Raster Storage
Traditional GeoTIFF files weren’t designed with cloud storage in mind. Reading these files often required downloading entire datasets, even when only a small portion was needed.
The introduction of COGs marked a significant shift, enabling efficient partial reads through HTTP range requests.
COGs achieve this efficiency through their internal structure:
- An initial header containing the Image File Directory (IFD)
- Tiled organization of the actual image data
- Overview levels for multi-resolution access
- Strategic placement of metadata for minimal initial reads
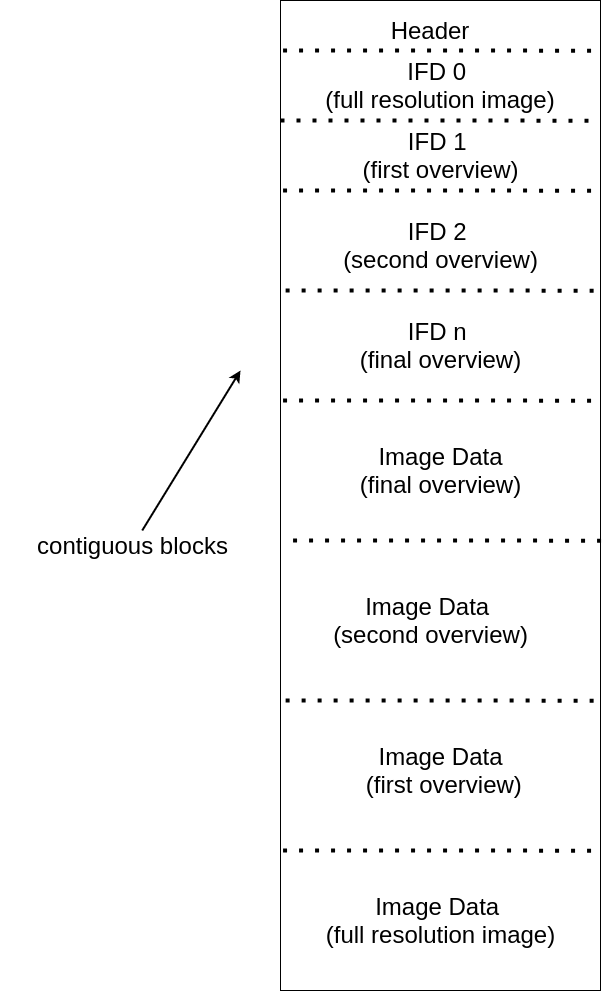
This structure allows tools to read specific portions of the file without downloading the entire dataset.
However we feel that even with COGs, trying to do something like a Time-series NDVI graph for a few polygons across a few regions is not as fast as it could be, especially due to the latency caused by AWS S3 throttling.
The STAC Ecosystem and GeoParquet
The SpatioTemporal Asset Catalog (STAC) specification has emerged as a crucial tool for discovering and accessing Earth observation data. While STAC APIs provide standardized ways to query satellite imagery, the Cloud Native Geospatial (CNG) community took this further by developing STAC GeoParquet.
STAC GeoParquet leverages Parquet’s columnar format to enable efficient querying of STAC metadata. The columnar structure allows for:
- Filter pushdown for spatial and temporal fields
- Efficient compression of repeated values
- Reduced I/O through column pruning
- Fast parallel processing capabilities with the right parquet reading libraries
Current access patterns and challenges
The current approach to accessing COGs, exemplified by GDAL and Rasterio, typically involves:
- Initial GET request to read the file header
- Additional requests if needed if header not found in initial request
- Final requests to read the actual data tiles
For cloud-hosted public datasets, this pattern can lead to:
- Multiple HTTP requests per file access
- Increased latency, especially across cloud regions
- Potential throttling on public buckets
- Higher costs from numerous small requests to paid buckets
A New Approach: Extending STAC GeoParquet and Byte-range calculations
Extending stac-geoparquet with new columns
Building upon the excellent stac-geoparquet, we explored adding some of COG’s internal metadata information directly into it.
We added new columns to the geoparquet, which were “per-band metadata” columns, containing the following information about each band’s COG file –
- Tile offset info
- Tile size info
- Data type
- Compression info
So for Sentinel 2, this was 13 new columns containing a dictionary of the above new data points derived by reading the headers of each COG file. We do a batch process and we pay the cost and time spent to gather COG files metadata upfront.
In our case we took 1 year’s worth of Sentinel 2 items from STAC API for this.
Get data from URLs by calculating byte ranges just-in-time
Now that we have 1 year’s worth of STAC items in GeoParquet along with each COG’s internal metadata. We can do what GDAL does behind the scenes without needing to query the headers of COG files again and again.
We use the info related to tile offsets and tile size info, to calculate the exact byte-range required to be read for each AOI for each COG URL in STAC items.
We then use Python requests module to get the data from the COG URLs, decompress the incoming bytes, since the data resides as deflate compressed COGs, and create the Numpy array.
Below is the current approach to reading a remote COG URL using Rasterio.
# Current approach with GDAL/rasterio requires
# multiple http requests per file behind the scenes
# find scenes from STAC APIs:
import rasterio
from pystac_client import Client
AOI_POLYGON = Polygon([(77.5, 13.0), (77.55, 13.0),
(77.55, 13.05),(77.5, 13.05),(77.5, 13.0)])
client = Client.open("https://earth-search.aws.element84.com/v1")
search = client.search(
collections=["sentinel-2-l2a"],
datetime=f"{start_date.isoformat()}/{end_date.isoformat()}",
intersects=mapping(AOI_POLYGON),
query={"eo:cloud_cover": {"lt": 20}}
)
items = list(search.get_items())
for item in items:
# First request to get IFD and headers of a file
src = rasterio.open(item.assets['red'].href)
# Second or third may happen behind the scene by GDAL
# if headers are not completely read in 1 http request
# once its read, rasterio open dataset is assigned
epsg = item.properties["proj:epsg"]
utm_polygon = wgs84_polygon_to_utm(AOI_POLYGON, epsg)
geojson = utm_polygon.__geo__interface
# using src now, we can ask GDAL to do the byte-range based request
# to get only those internal tiles of COG that cover our AOI
# and it returns a numpy array and its transform
data, transform = rasterio.mask(src, geojson, crop=True)
Current Approach
And below is is our approach.
from rasteret.metadata import CreateStacGeoParquet
from rasteret import StacGeoParquetFilter
from rasteret import TileFetcher
# Spend some time reading internal structural info for each COG file
# from STAC API endpoint for large date range and create
# a Sentinel 2 STAC geoparquet with the extra columns
metadata_dir = "sentinel2_metadata"
start_date = "2024-01-01"
end_date = "2024-12-31"
CreateStacGeoParquet(start_date, end_date, metadata_dir)
# Filter local Sentinel 2 STAC GeoParquet on Shapely Polygon, date range,
# required bands, and any extra pystac filters
filter = StacGeoparquetFilter(metadata_dir)
scenes = filter(
polygons=[AOI_POLYGON],
start_date=start_date,
end_date=end_date,
bands=['B04', 'B08'],
filters={'eo:cloud_cover': {'lt': 20}}
)
# After filtering geoparquet, we get data for each scene
for scene in scenes:
epsg = scene.values()['proj:epsg']
utm_polygon = wgs84_polygon_to_utm(AOI_POLYGON, epsg)
numpy_array, transform = TileFetcher.fetch_data(scene, utm_polygon)
# fetch_data calculates the byte-ranges required for the polygon,
# as per the scence, and fires 1 HTTP requestOur New Approach
Performance Insights
Initial benchmarks show promising results for this approach. The aim was to improve time-to-first-tile.
There are a few things to note before we get to some raster query speed tests –
It is important to tune GDAL configurations correctly to fully benefit from GDAL’s own multi-range requests, and use settings that avoid GDAL reading all S3 files which wastes time.
Rasterio with GDAL’s cache gets faster with subsequent reads to the same COG S3 file, but if the analysis is across time and space, then we pay the latency time to get headers per new file that is not cached.
This is also true across new VMs/Lambdas/Serverless compute, because a new Rasterio session will always be created for each run of your Python code in a new Python environment, so scaling out to multiple VMs means these new envs keep sending HTTP requests to each COG file it interacts with, to complete the rasterio.mask task.
Our approach to add new columns to STAC GeoParquet avoids paying this time and cost of multiple HTTP requests every time, for each new file and each new Python process.
We have made a custom python code for byte-range calculation code based on GDAL’s C++ approach. We also created custom tile merging code as well incase 1 AOI intersects with more than 1 internal tile of a COG.
This allows our library to be pretty lightweight and not require any GDAL dependencies, except for the geometry_mask/rasterize functions.
With all this context set, below are some initial test results –
Machine config – 2 CPU (4 threads), 2GB RAM machine
Test scenario: Processing 20 Sentinel-2 scenes for NDVI calculation over a year for a single farmland in India, with async Python functions
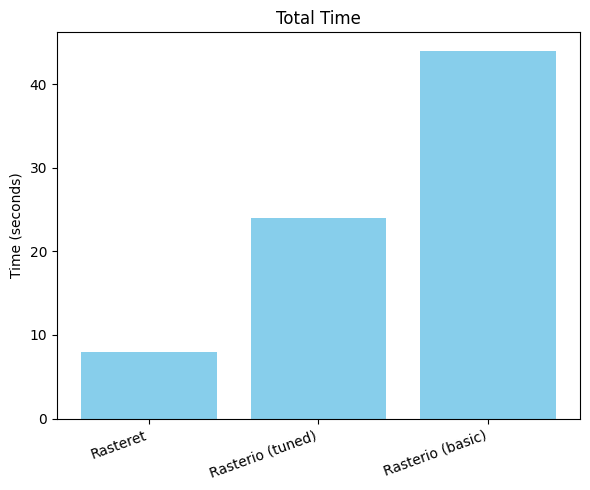
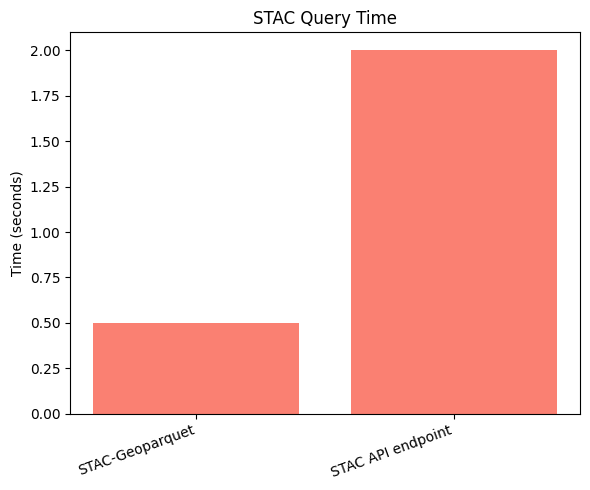
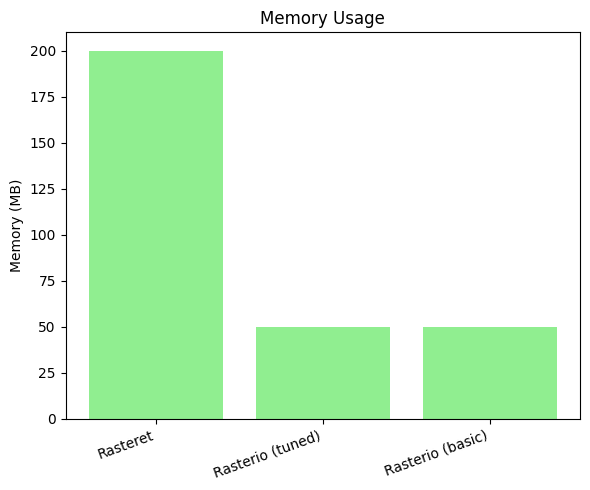
Key Factors to speed up in our approach:
- Reduced HTTP requests through pre-calculating byte ranges just-in-time for each AOI for each COG file
- Pre-cached metadata in STAC-GeoParquet eliminating API calls to STAC API JSON endpoints
- Optimized parallel processing for spatio-temporal analysis
Current Scope and Limitations
While these initial results are encouraging, it’s important to note where this approach currently works best:
Optimal Use Cases:
- Time-series analysis of Sentinel 2 data across multiple small polygons
- Optimize paid public bucket data access, to reduce GET requests costs
Areas of improvement:
- Pure Python or Rust implementations of operations like rasterio.mask
- Adding more data sources like USGS Landsat and others
- LRU or other cache for repeated same tile queries
- Reducing memory usage
- Benchmark against Xarray and Dask workloads
- Test on multiple polygons across the world for 1 year date range
What next:
As we continue to develop and refine this approach, we’re excited to engage with the geospatial community to gather feedback, insights, and contributions. By collaborating and building upon each other’s work, we can collectively push the boundaries of what’s possible with cloud-based raster data access and analysis.
We’re currently working on an open-source library which will be called “Rasteret” that implements these techniques, and we look forward to sharing the library and more technical details in an upcoming deep dive blog. Stay tuned!
Acknowledgments
This work stands on the shoulders of giants in the open-source geospatial community:
- GDAL and Rasterio, for pioneering geospatial data access
- The Cloud Native Geospatial community for STAC and COG specifications
- PyArrow and GeoArrow for efficient parquet filtering
- The broader open-source geospatial community
We’re grateful for the tireless efforts and contributions of these projects and communities. Their dedication, expertise, and willingness to share knowledge have laid the foundation for approaches like the one outlined here.
Terrafloww is proud to support the Cloud Native Geospatial forum by being a newbie startup member in their large established community.

Keep your files stored safely and securely with the SanDisk 2TB Extreme Portable SSD. With over 69,505 ratings and an impressive 4.6 out of 5 stars, this product has been purchased over 8K+ times in the past month. At only $129.99, this Amazon’s Choice product is a must-have for secure file storage.
Help keep private content private with the included password protection featuring 256-bit AES hardware encryption. Order now for just $129.99 on Amazon!
Support Techcratic
If you find value in Techcratic’s insights and articles, consider supporting us with Bitcoin. Your support helps me, as a solo operator, continue delivering high-quality content while managing all the technical aspects, from server maintenance to blog writing, future updates, and improvements. Support Innovation! Thank you.
Bitcoin Address:
bc1qlszw7elx2qahjwvaryh0tkgg8y68enw30gpvge
Please verify this address before sending funds.
Bitcoin QR Code
Simply scan the QR code below to support Techcratic.

Please read the Privacy and Security Disclaimer on how Techcratic handles your support.
Disclaimer: As an Amazon Associate, Techcratic may earn from qualifying purchases.








