
















































![[01_Odyssey] Generative art Exhibition – Dark Room Experience](https://techcratic.com/wp-content/uploads/2025/09/1758190693_maxresdefault-360x180.jpg)








































2025-01-08 09:30:00
www.mattkeeter.com
Introduction
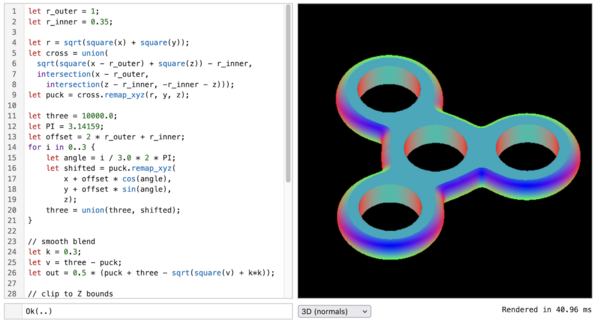
Fidget is a library for representing,
compiling, and evaluating large-scale math expressions, i.e. hundreds or
thousands of arithmetic clauses. It’s mainly designed as a backend for
implicit surfaces, but the
library is flexible enough for many different uses!
What are implicit surfaces?
Implicit surfaces are expressions of the form
$f(x, y, z) \rightarrow d$
returning a single distance value $d$.
If that value is positive, then the point $(x, y, z)$ is outside the model;
if it’s negative, then the point is inside the model.
For example, a sphere of radius 1 can be expressed
as
$$ f(x, y, z) = \sqrt{x^2 + y^2 + z^2} – 1 $$
By evaluating the expression at many points in space and checking its sign, we
can render this function into an image. In this example, we’ll render a
heightmap, where filled-in voxels are colored based on their distance to the
camera:

Fidget focuses on closed-form implicit surfaces, which build their
expressions out of basic arithmetic operations. This is in contrast with more
flexible representations (e.g. GLSL in a pixel shader), which may run entire
Turing-complete programs to compute the distance value.
I like to think of these functions as an “assembly language for shapes”: a
low-level representation that you’re unlikely to write by hand, but easy to
target from higher-level representations.
Why implicit surfaces?
Implicit surfaces are a particularly pleasant representation: they’re compact,
philosophically straight-forward, and amenable to massively parallel evaluation
(e.g. using SIMD instructions or on the GPU).
In addition, constructive solid geometry (CSG)
operations like union or intersection – famously difficult for meshes and NURBS
– are trivial! Here’s the union of two exactly-coincident cylinders,
which is just min(a, b):

Having a closed-form equation opens the door to interesting optimizations. For
example, Fidget can capture a trace showing which branches are taken during
evaluation; this trace can be used to simplify the expression, reducing the cost
of future evaluation.
Finally, for the computer enthusiasts, implicit surfaces offer a deep well of
entertaining research topics: everything from compilers to meshing algorithms
to GPGPU programming.
In other words, I just think they’re neat.
Origins
Over the past ten years, I’ve spent a lot of time thinking about
rendering and evaluation of implicit surfaces:
- I’ve written 4-5 kernels
in various languages, at least one of which was used
in commercial CAD software. - Back in 2020, I published a SIGGRAPH paper presenting a new
strategy for fast rendering on modern GPUs
So, why write something completely new, when the industrial-strength libfive
kernel is sitting right there?
This is personal-scale, mostly-unpaid research, so I have to optimize
for my own motivation and energy. The questions that I’m currently finding
interesting would be hard or frustrating to investigate using libfive as a
foundation:
- Finding the “right” APIs for implicit kernels, with the possibility of making
substantial compatibility breaks - Experimenting with native (JIT) compilation, to improve performance without
moving to the GPU - Cross-compiling to WebAssembly and building easily-accessible web demos
libfive is 40K lines of mostly C++, and is extremely challenging to hack on,
even as the original author. It’s also frustrating to touch: if it’s been a few
months since I last compiled it, it’s inevitable that the build will have
broken, and I’ll have to mess with CMake for 10 minutes to unbreak it.
Fidget is written in Rust, which I’m also using
professionally. It compiles
with a single cargo build, cross-compiles to WebAssembly seamlessly, and can
be refactored with confidence (thanks to Rust’s strong type system and memory
safety).
With all that context, let’s get started on our tour of the library!
Library structure
The library is built as a stack of three mostly-decoupled layers, along with
demo applications. Click on one to jump to that section of the writeup, or keep
scrolling to read through in order.
Frontend: building math expressions
The frontend of Fidget goes from input script to bytecode:

It’s not mandatory to use this specific workflow; users of the library can
show up at any point in this diagram.
Let’s walk through step by step and see how things look at each stage!
Scripting
Fidget includes bindings for Rhai, an embedded scripting
language for Rust. Using operator overloading, it’s easy to write scripts to
build up math expressions:
let scale = 30;
let x = x * scale;
let y = y * scale;
let z = z * scale;
let gyroid = sin(x)*cos(y) + sin(y)*cos(z) + sin(z)*cos(x);
let fill = abs(gyroid) - 0.2;
let sphere = sqrt(square(x) + square(y) + square(z)) - 25;
draw(max(sphere, fill));
The value passed to draw is a math tree which represents the expression
built up by the script.
Tree and graph
The math tree is deduplicated to produce a directed acyclic graph:

SSA tape
Doing a topological sort
lets us flatten the graph into straight-line code.
This code is in single static assignment form;
there are arbitrarily many pseudo-registers (named rX), and each one is only
written once.
r7 = Input[0]
r6 = MulRegImm(r7, 30.0)
r26 = SquareReg(r6)
r16 = Input[2]
r15 = MulRegImm(r16, 30.0)
r25 = SquareReg(r15)
r24 = AddRegReg(r26, r25)
r10 = Input[1]
r9 = MulRegImm(r10, 30.0)
r23 = SquareReg(r9)
r22 = AddRegReg(r24, r23)
r21 = SqrtReg(r22)
r20 = SubRegImm(r21, 25.0)
r19 = SinReg(r6)
r18 = CosReg(r15)
r17 = MulRegReg(r19, r18)
r14 = SinReg(r15)
r13 = CosReg(r9)
r12 = MulRegReg(r14, r13)
r11 = AddRegReg(r17, r12)
r8 = SinReg(r9)
r5 = CosReg(r6)
r4 = MulRegReg(r8, r5)
r3 = AddRegReg(r11, r4)
r2 = AbsReg(r3)
r1 = SubRegImm(r2, 0.2)
r0 = MaxRegReg(r20, 1)
Output[0] = r0
It’s possible to evaluate this tape, but it doesn’t scale well: you have to
allocate a memory location for every single operation, since pseudo-registers
aren’t reused.
Bytecode
To improve evaluation, it’s helpful to map from pseduo-registers to
physical(ish) registers, which can be reused.
For example, the tape above can be packed into 6 reuseable registers:
r3 = Input[0]
r3 = MulRegImm(r3, 30.0)
r0 = SquareReg(r3)
r4 = Input[2]
r4 = MulRegImm(r4, 30.0)
r2 = SquareReg(r4)
r0 = AddRegReg(r0, r2)
r2 = Input[1]
r2 = MulRegImm(r2, 30.0)
r1 = SquareReg(r2)
r0 = AddRegReg(r0, r1)
r0 = SqrtReg(r0)
r0 = SubRegImm(r0, 25.0)
r1 = SinReg(r3)
r5 = CosReg(r4)
r1 = MulRegReg(r1, r5)
r4 = SinReg(r4)
r5 = CosReg(r2)
r4 = MulRegReg(r4, r5)
r1 = AddRegReg(r1, r4)
r2 = SinReg(r2)
r3 = CosReg(r3)
r2 = MulRegReg(r2, r3)
r1 = AddRegReg(r1, r2)
r1 = AbsReg(r1)
r1 = SubRegImm(r1, 0.2)
r0 = MaxRegReg(r0, r1)
Output[0] = r0
Register allocation uses the simple algorithm that I
blogged about a few years back. It’s a single-pass algorithm that trades
efficienty for speed and determinism; that blog post has much more detail and
interactive demos.
The bytecode interpreter uses 256 registers, so the register index is stored in
a u8. If we run out of registers, then the allocator inserts LOAD and
STORE operations to write to secondary memory (using a u32 index).
This bytecode tape is the end of the front-end; we now proceed to the backend
for evaluation!
Backend: fast, flexible evaluation
The Fidget backend is decoupled from the front-end with a set of traits
(Function,
TracingEvaluator, and
BulkEvaluator),
which roughly represent “things that can be evaluated”.
This decoupling means that algorithms can target a generic Function, instead
of being tightly coupled to our math tree implementation. Right now, there
aren’t any non-math-tree implementers of the Function trait, but this could
change in the future. In the current implementation, we have two different
flavors of math tree evaluation: interpreted bytecode, and JIT-compiled
functions.
Here’s a high-level sketch of the evaluation process:

For our math expressions, the Tape object is the same bytecode tape that we
constructed earlier. The Evaluator is a very simple interpreter, which
iterates over the bytecode tape and executes each opcode.
There are four different evaluation modes:
- Single-point and array (SIMD) evaluation
- Forward-mode automatic differentiation
- Interval arithmetic
Bulk and SIMD evaluation
Bulk evaluation is straight-forward: the user provides an array of input values,
and receives an array of outputs. When using the JIT backend, we generate SIMD
code which processes 4 (AArch64) or 8 (x86-64) element at a time.
$$ [1, 2, 3, 4] + [5, 6, 7, 8] = [6, 8, 10, 12]$$
Forward-mode automatic differentiation
The derivative evaluator calculates both a value and up to three partial
derivatives (with respect to some variables). For implicit surfaces, it’s
typically used to calculate the tuple
$$(f, \frac{\partial f}{\partial x}, \frac{\partial f}{\partial y}, \frac{\partial f}{\partial z})(x, y, z)$$
At the surface (where $f(x, y, z) = 0$), the partial derivatives are a good
approximation of the surface normal, which can be used for shading:
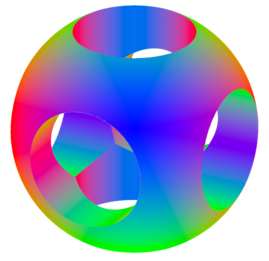
Evaluation uses forward-mode automatic differentiation;
values in registers are augmented with derivatives, and the chain rule is used
at each step of evaluation. The JIT evaluator packs the value and three
derivatives into a single 4 x f32 register for efficiency.
Interval arithmetic
Interval arithmetic lets us evaluate expressions over ranges of input values:
instead of assigning $x = 1$, we can say $1 \le x \le 5$. The output will also
be an interval, e.g. $2 \le f(x, y, z) \le 20$.
The results of interval arithemetic are conservative: they may not tightly bound
the true range of the function, but they are guaranteed to contain all possible
outputs (for input values within the given input intervals).
Interval arithmetic is a core building block for evaluation of implicit
surfaces. If you evaluate a spatial region (using intervals for $x$, $y$, $z$)
and find an interval that’s unambiguously greater than 0, that entire region is
outside your shape and doesn’t need to be considered any further!
In the render below, green and red regions were proved inside / outside the
shape by interval arithmetic; only the black and white pixels were evaluated by
the point-wise evaluation.

Skipping regions based on interval arithmetic results is already a significant
optimization over bulk evaluation, but wait – there’s more!
Tracing evaluation and simplification
Our interval arithmetic evaluator also captures a trace of its execution.
For example, consider the following min, evaluated using interval arithmetic:
$$\min(a, b) \text{ where } 0 \le a \le 1 \text{ and } 4 \le b \le 5$$
Because $a$ is unambiguously less than $b$ (within this interval), the
expression can be simplified from $\min(a, b) \rightarrow a$.
Each min and max operation records a single choice, indicating which
arguments affect the result (left-hand side, right-hand side, or both). These
choices can be used to simplify the original function. In our $\min(a, b)$
example, we don’t need to calculate $b$ or $\min$ if we’ve simplified the
expression to just $a$.
The One Weird Trick
The combination of interval arithmetic and tape simplification is the One Weird
Trick that makes working with large-scale expressions feasible. I’m going to
circle around this idea from a few different angles, because it’s critically
important!
Interval arithmetic and tape simplification have a positive synergy: we can both
skip inactive (empty / full) regions of space, and evaluating the remaining
active regions becomes cheaper.
You can also think of tape simplification as analogous to a spatial acceleration
data structure: we’re computing a simplified expression that’s only valid in a
particular spatial region. Unlike typical raytracing acceleration data
structures, we’re building the accelerator dynamically during evaluation.
For rasterization, the cost of interval evaluation is amortized across many
pixels in the interval. Interval evaluation of an $N \times N$ pixel region
with a tape length of $T$ is $O(T)$, i.e. only proportional to the tape length,
and independent of pixel count.
By the time we get down to single-pixel evaluation (e.g. for an $M \times M$
region, $M
Both of these effects are even more significant for 3D rendering, where we’re
dealing with $N^3$ voxels instead of $N^2$ pixels!
To get some concrete numbers, let’s take a closer look at the hello, world
image above. We’re rendering a 256×256 image (2D), and the original tape is 254
clauses. Here’s how things go down:
- Interval evaluation of 32×32 pixel tiles, of which there are 64
- Empty regions are skipped, leaving 47 active tiles
- The average tape length in active tiles has shrunk to 73 clauses
- Each of these tiles is subdivided into 16 smaller tiles (8×8 pixel)
- Interval evaluation of 8×8 pixel tiles, of which there are 752
- Empty regions are skipped, leaving 351 active tiles
- The average tape length in active tiles has shrunk to 20 clauses
- Per-pixel evaluation of remaining 8×8 pixel tiles, of which there are 351
Here are the active tiles positions and tape lengths after simplification:
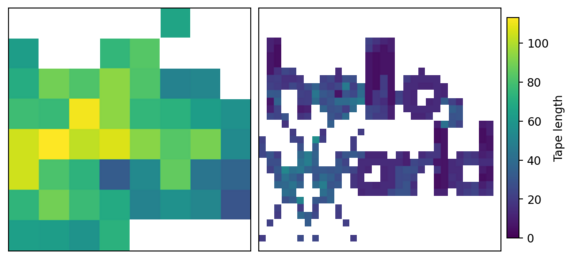
By the time we’re doing per-pixel evaluation, the tape is more than 10× shorter
than its original length!
Of course, not every shape is amenable to this kind of on-the-fly
simplification. Fidget supports simplifying min and max operations (used in
CSG), as well as logical ops (and and or). Shapes without CSG or logic
won’t benefit from simplification; however, they may still benefit from
interval-arithmetic-based skipping of empty and full regions.
JIT compilation
The bytecode interpreter is a tight loop, but suffers from inevitable overhead:
- Instruction dispatch is a single unpredictable branch
(see “Beating the compiler”
for details on interpreter optimization) - Each instruction reads and writes to memory, in the form of register slots
within the VM evaluator
For maximum performance, Fidget also includes a JIT compiler, which lowers
bytecode down to machine instructions! The machine instructions are
straight-line code (without any dispatch), and use physical registers directly
(so no reading and writing to memory).
Consider $\sqrt{x^2 + y^2} – 1$, which generates the following bytecode:
r0 = Input[1]
r0 = SquareReg(r0)
r1 = Input[0]
r1 = SquareReg(r1)
r0 = AddRegReg(r0, r1)
r0 = SqrtReg(r0)
r0 = SubRegImm(r0, 1.0)
Output[0] = r0
The input to the JIT compiler is the same bytecode tape as before, but planned
with 12 (x86-64) or 24 (AArch64) physical registers, instead of the VM
default of 255. (This isn’t visible in the bytecode above, which only uses two
registers)
These register limits mean that bytecode registers can directly be mapped to
physical registers in hardware: v8-31 on AArch64, and xmm4-15 on x86-64.
With the help of godbolt.org, I hand-wrote snippets of
assembly for every single opcode × data type × architecture. This was very
tedious! However, it makes JIT compilation simple: patch in the desired
physical registers within each snippet, then copy them into an mmap‘d region
of memory.
The bytecode above is turned into the following function on an AArch64 system:
; Preserve frame and link register, and set up the frame pointer
stp x29, x30, [sp, 0x0]
mov x29, sp
; Preserve callee-saved floating-point registers
stp d8, d9, [sp, 0x10]
ldr s8, [x0, 4] ; r0 = Input[1]
fmul s8, s8, s8 ; r0 = SquareReg(r0)
ldr s9, [x0, 0] ; r1 = Input[0]
fmul s9, s9, s9 ; r1 = SquareReg(r1)
fadd s8, s8, s9 ; r0 = AddRegReg(r0, r1)
fsqrt s8, s8 ; r0 = SqrtReg(r0)
movz w9, 0x3f80, lsl 16 ; load 1.0 into s3
fmov s3, w9
fsub s8, s8, s3 ; r0 = SubRegImm(r0, 1.0)
str s8, [x1, 0] ; Output[0] = r0
; Restore frame and link register
ldp x29, x30, [sp, 0x0]
; Restore callee-saved floating-point registers
ldp d8, d9, [sp, 0x10]
ret
At the Rust level, this chunk of memory can be cast to a function pointer, i.e.
unsafe extern "C" fn(
*const f32, // x0: inputs
*mut f32 // x1: outputs
);
Rust slices can be cast to raw pointers for inputs and outputs, e.g.
let in = [0.0, 1.0]; // [x, y]
let mut out = [0.0];
unsafe {
(fn_ptr)(in.as_ptr(), out.as_mut_ptr());
}
println!("{out:?}");
JIT compilation has a dramatic effect on evaluation time. Here’s a relatively
complex example, built from 7867 expressions:

Doing brute force evaluation on 1024² pixels, the bytecode interpreter takes 5.8
seconds, while the JIT backend takes 182 milliseconds – a 31× speedup!
Note that the speedup is less dramatic with smarter algorithms; brute force
doesn’t take advantage of interval arithmetic or tape simplification! The
optimized rendering implementation in Fidget draws this image in 6 ms using the
bytecode interpreter, or 4.6 ms using the JIT backend, so the improvement is
only about 25%.
Algorithms
With a foundation of fast evaluation, the sky’s the limit!
Rendering
All of the models in this writeup are rendered using algorithms from
fidget::render.
Rendering uses the same core algorithm presented in my SIGGRAPH
paper:
- Render large spatial regions using interval arithmetic
- Generate shortened tapes based on traces
- Subdivide and recurse on ambiguous regions
- Calculate normals using partial derivatives (3D rendering only)
(There’s nothing particularly exotic here, for folks familiar with the
literature; it’s a particularly well-tuned implementation of ideas dating back
to the 90s)
Models are transformed by a 4×4 homogeneous matrix as part of rendering, which
means that perspective transforms are supported. Rendering typically produces
two images: a heightmap, and per-pixel normals.
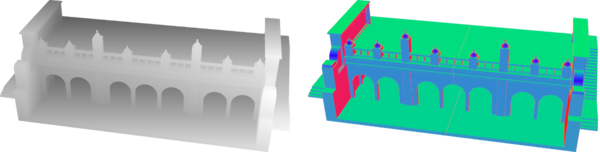
These can be drawn using standard deferred rendering techniques, e.g.
SSAO
(left as an exercise for the reader).
Meshing
Fidget implements Manifold Dual Contouring for meshing.

The implementation in Fidget should always produce meshes that are
- Watertight
- Manifold
- Preserving sharp features (edges / corners)
- Adaptive; triangles are less dense in mostly-flat regions
However, it has the following deficiencies:
- It will not necessarily preserve thin features
- The resulting meshes may include self-intersections
- Vertex positioning is susceptible to adversarial cases
Looking closely at the model, the topology leaves something to be desired:

It may seem weird to write out all of the ways meshing can go wrong – why not
just make it better? – but good meshing of arbitrary implicit surfaces remains
an unsolved problem!
Whenever someone publishes a new meshing strategy, I go through my checklist and
see how it scores; Manifold Dual Contouring, while not perfect, currently
occupies a sweet spot of simplicity and performance.
Demos
The Fidget repository includes
a handful of demos, with a
great deal of implementation variety.
I’d like to focus on the web GUI, because it’s the most interesting; there’s
also a simple CLI (fidget-cli) and native script viewer (fidget-viewer).
You may remember the web editor from the very beginning of the writeup, some
3000 words ago! You can still try it out:
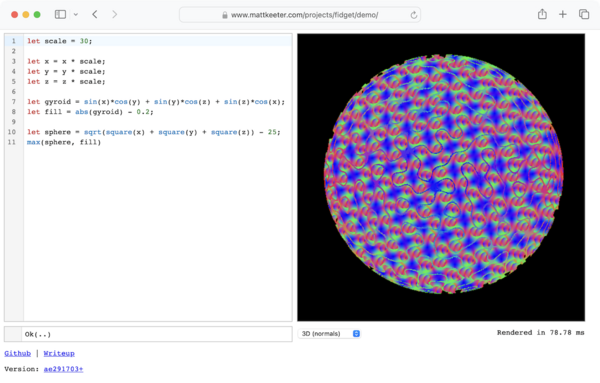
This demo was an opportunity for me to explore more modern (and in some cases,
bleeding-edge) web development. There’s a lot going on:
- The GUI is written in TypeScript!
- The Fidget crate is used as a library, rather than driving the event loop.
- The text editor is CodeMirror, so I have to use
Node modules… - …which requires a bundler; I picked webpack
somewhat arbitrarily. - Script evaluation and rendering are both done by web worker threads, to avoid
blocking the main event loop. - Rendering is parallelized, using
wasm-bindgen-rayonto
work around the lack ofstd::threadin the browser. - Workers share memory with the main event loop. We can cancel long-running
renders if the user provides new input, by setting a flag in an
Arcthat’s shared with the worker thread.
All of this was a terrible nightmare! Each individual component deserves praise
for including a working example; unfortunately, they all used mutually exclusive
bundlers, settings, servers, etc. Combining them all into a working system was
quite a challenge!
(For example, I had to pin an old version
of wasm-bindgen
because they recently fixed a bug that was load-bearing for
wasm-bindgen-rayon)
Still, I’m pleased with how it turned out. It even works on my phone, albeit
without camera controls (since I’m using mouse events instead of touch events).
Aside: Meditations on demos
I always have mixed feelings about making demos for my projects. Fidget is
first and foremost a library; people should be embedding it into their own
projects as infrastructure, not using my demos as actual CAD tools.
However, the population of Weird CAD People (which is small to begin with!)
breaks down into roughly the following groups:

Many more people will be interacting with the demos – even to the point of
using them for design work – than building tools with the libraries. There’s a
tension between making the demos more useful for this larger audience, versus
making the libraries better for a smaller set of users.
Historically, I’ve struggled to maintain a kernel and full-fledged CAD UI
simultaneously, and have been reducing the scope of demos accordingly – but as
you can tell from the web editor, even a “minimal” demo is a significant
project.
I don’t know how this will turn out with Fidget! My plan is roughly the
following:
- Keep following my interests, to preserve my motivation and focus
(the most limited resources!) - Accept suggestions from people using the tools, while setting expectations at
a reasonable level - Prioritize feedback from people in the smaller circles of tool-builders,
because – in an ideal world – they would take pressure off my demos by
building full-fledged tools that others could use
Future possibilities
I’ve been quietly working on Fidget for about 2.5 years. In that time, it has
evolved significantly – for example, it started as an LLVM-backed evaluator! I
expect it to continue evolving, albeit at a slower pace, as I continue to find
the “right” APIs and abstractions.
Let me discuss a few obvious future directions, before wrapping up.
Doing stuff on the GPU
I wrote a whole paper about this, so adding a GPU backend
seems like an obvious extension. In fact, I have already done this, in the
wgpu-bytecode branch!
However, performance isn’t particularly compelling, at least on my Apple M1 Max
laptop. In particular, the bytecode interpreter loop appears to be incredibly
inefficient. I’m continuing to investigate the root cause, and will likely
write up a blog post with more details.
(If you’re familiar with Metal shader optimization, feel free to reach out, and
I will happily brain-dump in your direction)
Better meshing
For serious users of the library, this is the elephant in the room. Fidget is
using the same meshing strategy as libfive, but without a bunch of fine-tuning
that makes the latter more robust.
I haven’t spent much time on this, because I’m fundamentally unsatisfied with
the available options. I would rather spend time implementing a bulletproof
meshing algorithm, rather than adding epicycles to dual contouring.
Unfortunately, I haven’t seen anything in the literature that meets my
requirements, and haven’t yet devised anything better myself.
We’ll see how things shake out! Depending on user demand, I would probably be
willing to do some fine-tuning, but also want to keep an eye out for better
options.
Standard library of shapes and transforms
Over the past few generations of software, I’ve been porting the
Fab Modules‘s
standard library of shapes into each new tool. This is tedious, but gives a
somewhat-standard foundation for higher-level modeling.
libfive hit a high point in complexity, where I wrote each shape in C++, then
automatically generated C, Python, and Scheme bindings from the header file.
The explanation in the
README
has a certain “statements dreamed up by the utterly deranged” energy to it:
libfive_stdlib.his both a C header and a structured document parsed by a
helper script.
We’re still brainstorming the right approach for Fidget; see
fidget#145 for ongoing
discussions.
Dragging the fab shapes
library into Rust would work, but I’m wondering if we can do better – for
example,
Inigo Quilez’s library of primitives
takes advantage of GLSL vectors to produce much more elegant code.
Bindings to higher-level languages
I’m a big fan of wrapping interactive shells around a compiled core. Right now,
Fidget only has bindings to Rhai, which was chosen because
it’s one of the few mature Rust-first scripting languages. Rhai has been very
easy to integrate (and I love that it compiles into WebAssembly), but I suspect
that most users would prefer Python or Node bindings.
Then, there’s the question of how to write those bindings: a C API would let
people lean on the FFI libraries of their favorite languages, but feels like a
step down from Fidget’s Rust-first design. Similarly, once we have a standard
library (discussed above), it would be great for it to be automatically exposed
in each binding, with proper ergonomics (docstrings, default arguments, etc).
As always, feel free to reach out if you have thoughts!
Conclusion
Ever since initial publication, Fidget’s README has described it as “quietly
public”; 19 versions have been published to
crates.io,
and a few people have started to build on it,
but I haven’t been talking about it outside of semi-private spaces.
This blog posts marks the end of the quietly public phase:
it’s now loudly public.
Go try it out, build some stuff, tell your friends, and
let me know
how it goes!
The source code is on Github
and can be added to a Rust project with cargo add fidget.
It is released under a weak copyleft license
(MPL 2.0),
which is friendly for both OSS and commercial usage.
Thanks to everyone who contributed to this post and the project as a whole:
Martin Galese,
Bruce Mitchener,
Avi Bryant,
Blake Courter,
Johnathon Selstad,
Bradley Rothenberg,
Moritz Mœller,
Luke V,
and various others in all the group chats.

Keep your files stored safely and securely with the SanDisk 2TB Extreme Portable SSD. With over 69,505 ratings and an impressive 4.6 out of 5 stars, this product has been purchased over 8K+ times in the past month. At only $129.99, this Amazon’s Choice product is a must-have for secure file storage.
Help keep private content private with the included password protection featuring 256-bit AES hardware encryption. Order now for just $129.99 on Amazon!
Support Techcratic
If you find value in Techcratic’s insights and articles, consider supporting us with Bitcoin. Your support helps me, as a solo operator, continue delivering high-quality content while managing all the technical aspects, from server maintenance to blog writing, future updates, and improvements. Support Innovation! Thank you.
Bitcoin Address:
bc1qlszw7elx2qahjwvaryh0tkgg8y68enw30gpvge
Please verify this address before sending funds.
Bitcoin QR Code
Simply scan the QR code below to support Techcratic.

Please read the Privacy and Security Disclaimer on how Techcratic handles your support.
Disclaimer: As an Amazon Associate, Techcratic may earn from qualifying purchases.








{kind=link}